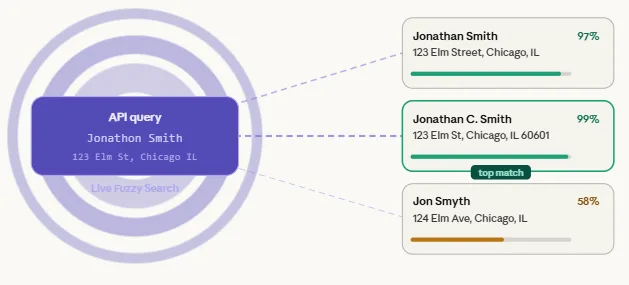
Live Fuzzy Search allows you to search any reference dataset in real time and instantly return the closest matches, even when the input is imperfect. It is designed for any scenario where you need to fuzzy match on the fly — names, clients, vendors, companies, patients, or addresses. One of its most powerful applications is duplicate detection at the point of entry: before a new record is saved to your system, you run it through Live Fuzzy Search and immediately see whether something similar already exists. That is how you prevent duplicates before they start.
Live Fuzzy Search is a standard module in your Match Data Pro workflow. This means it can receive data from any upstream module — you can import data and pass it directly to Live Fuzzy Search, run it through Cleansing first, process it through Entity Resolution, or even expose only the matched or unique records from a prior Match job. You can also add multiple Live Fuzzy Search modules to a single project, one for each dataset you want to search.
To add Live Fuzzy Search, open your project workflow, select it from the module list, and click Add. Once added, click Configure to open the configuration panel — you can also reach any module’s configuration from the left-hand menu.
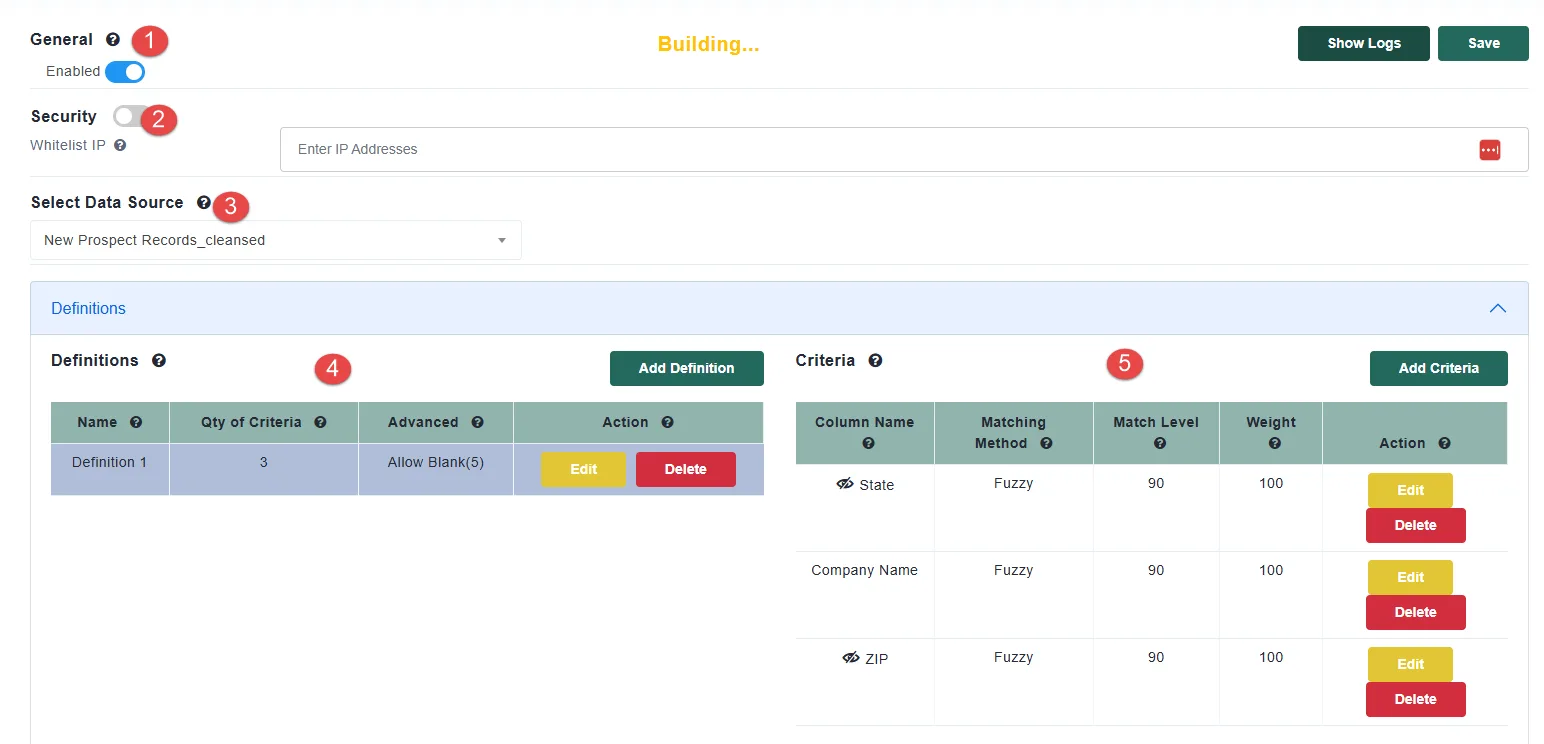
Before a search runs, Live Fuzzy Search can normalize the incoming record using cleansing rules. This is useful because your reference data has already been cleansed, and you want the incoming query to be comparable to it.
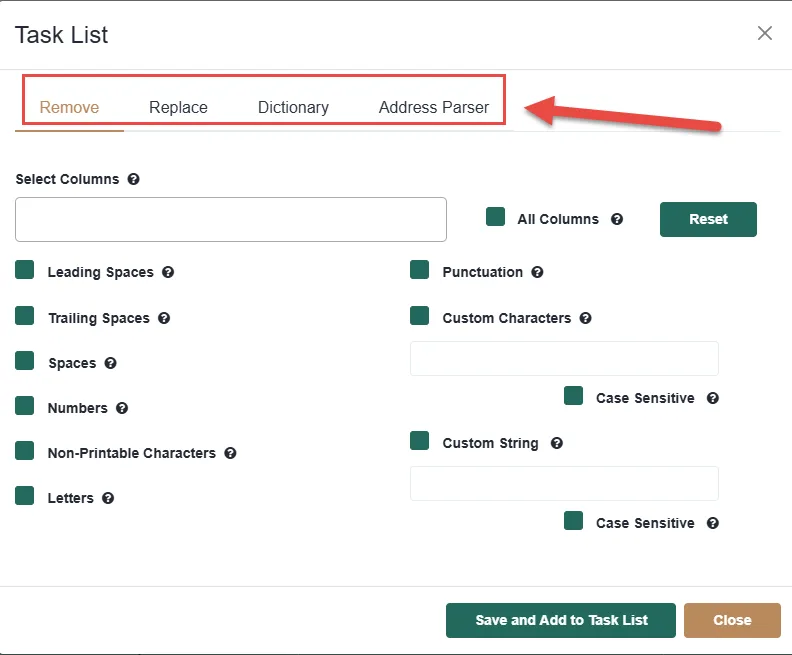
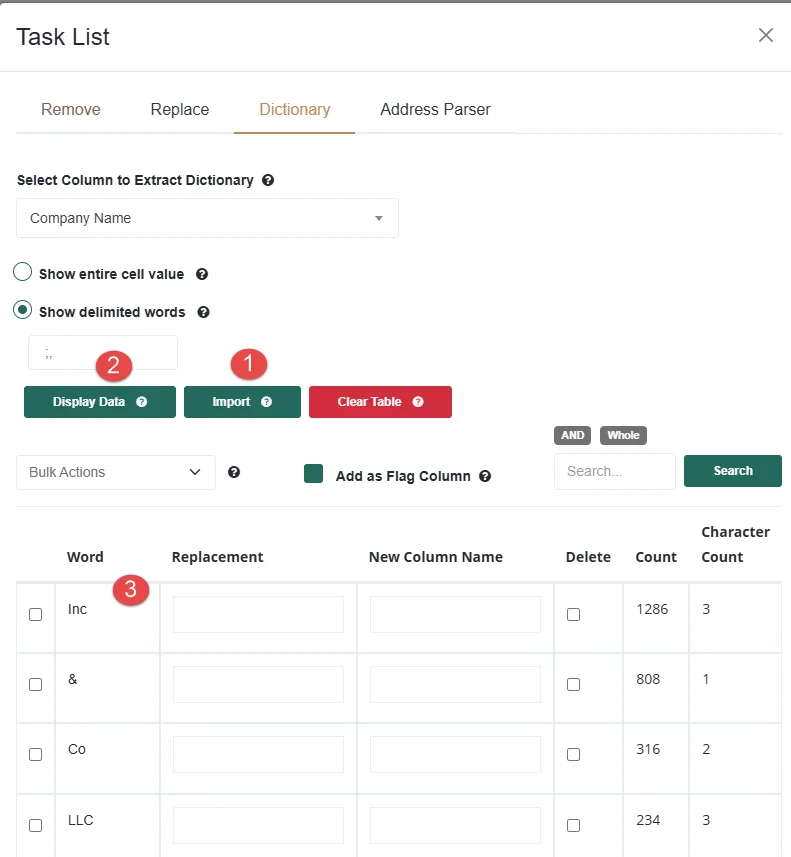
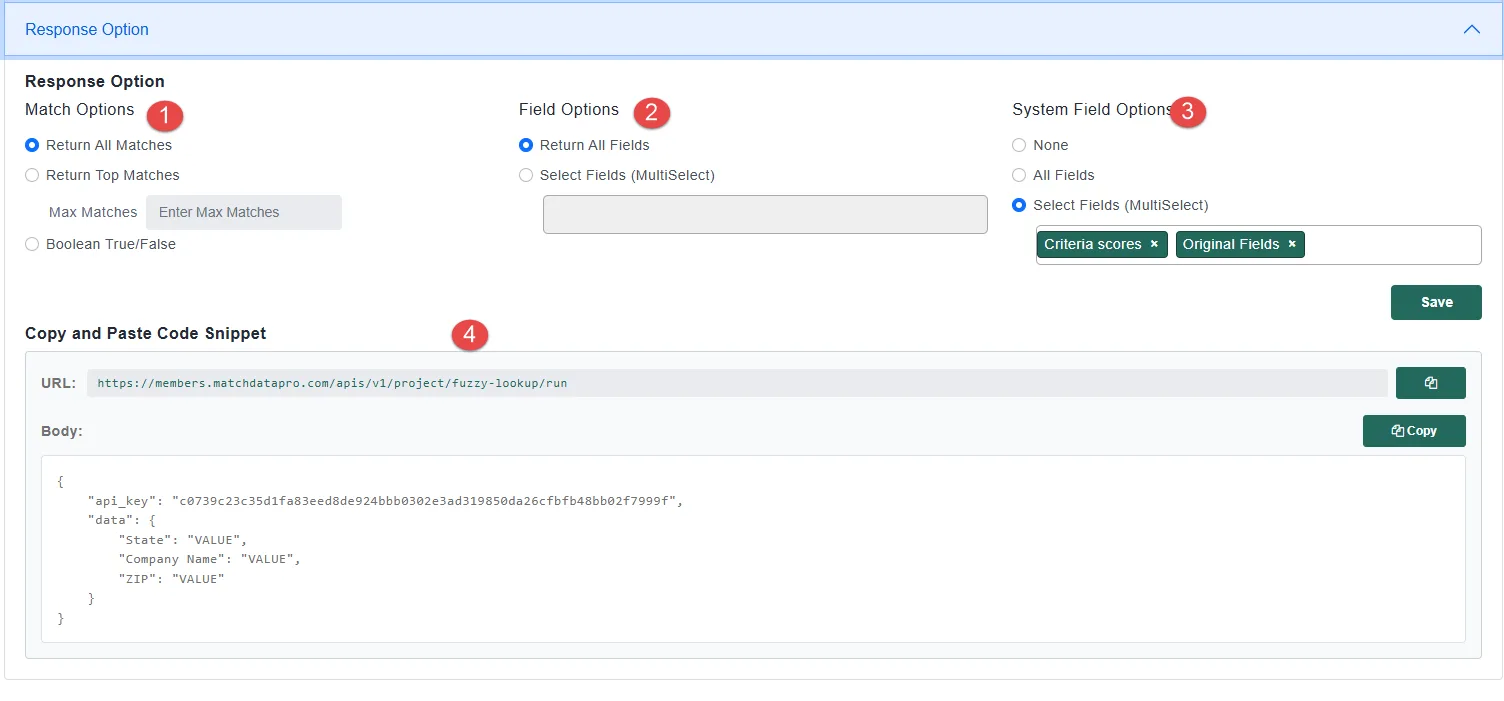
The Response Options section controls what Live Fuzzy Search returns when it finds matches. There are three categories.
Any reference dataset that exists as a data source in your Match Data Pro project. Common use cases include customer names, company names, vendor records, patient records, and addresses. If you can import it into MDP, you can expose it through Live Fuzzy Search.
Responses are designed to return in under one second. The exact speed depends on the size of your dataset and how many exact versus fuzzy criteria your configuration uses. Exact criteria process faster than fuzzy criteria, so using exact matching where precision allows will help keep response times as low as possible.
You can, but it is not recommended. Live Fuzzy Search is designed to search a cleansed reference dataset. The cleansing rules built into the module are intended to normalize incoming query records so they are comparable to your already-cleansed data source — not to replace a full cleansing pipeline on the reference data itself.
All matches returns every record that meets your match criteria, ranked by score. Top 1 returns only the single highest-scoring match. Boolean returns true if any match exists and false if none does. Use Boolean when you only need duplicate detection and do not need to know which record matched.
Yes. You can enter one or more allowed IP addresses in the configuration. Any API call originating from an address not on that list will be blocked. If you leave the IP allowlist empty, the endpoint is open to any caller who has the URL.
Nothing is interrupted. While the new data loads into memory, the current data continues to serve requests normally. Once the new index is fully built, the switchover happens in under one millisecond. There is no downtime and no gap in availability.
Yes. Match Data Pro allows multiple instances of the same module type within a single project. You can add one Live Fuzzy Search per dataset, each with its own configuration and endpoint.
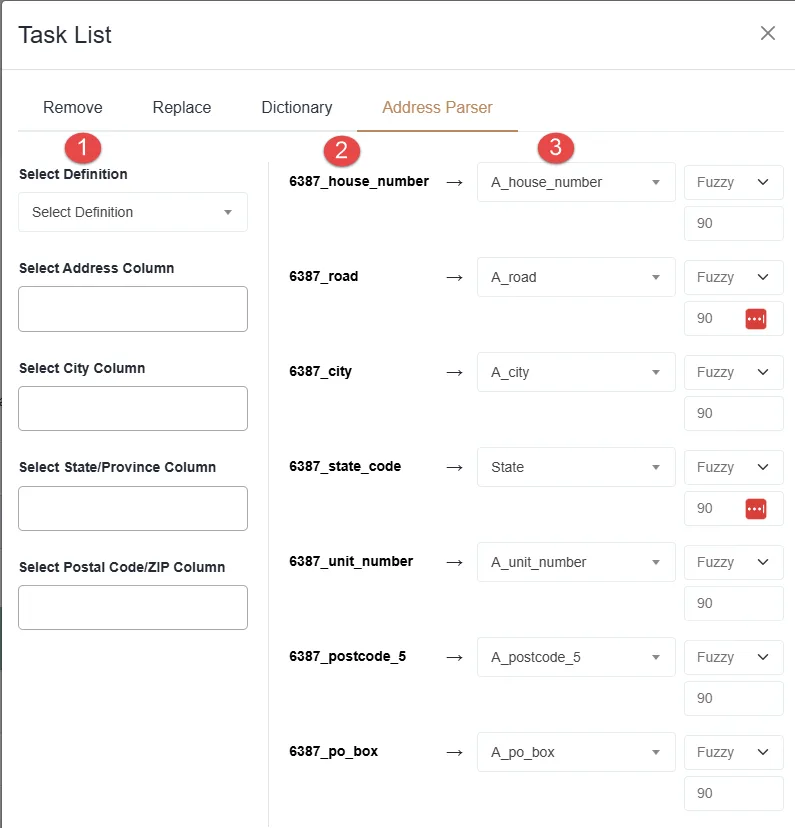
Standard criteria matching compares full address strings. The Address Parser breaks an address down into its individual components — house number, road name, city, state code, unit number, ZIP code, and PO box — and matches each component independently, with its own fuzzy or exact setting. This produces more accurate address matching, particularly when addresses contain abbreviations, missing unit numbers, or minor formatting differences.
Criteria Scores return the individual match score for each criterion in your definition, rather than just the overall definition score. This is useful when you want to understand exactly which fields drove a match or near-miss — for example, if a name matched at 98% but the address only matched at 60%.
Yes. When Original Fields is enabled, the API response echoes back the exact values you submitted in the query. This is helpful for logging, debugging, and confirming that your application is sending the expected input.
At Match Data Pro, our core focus is fuzzy data matching and entity resolution but our platform goes far beyond that
Copyright 2026 Match Data Pro. All Rights Reserved