

In the packaging industry, data is as vital as the products themselves. For a global packaging leader that produce billiones of containers annually across worldwide – the sheer volume and complexity of information can be overwhelming. Multiple production sites, countless suppliers, and diverse customer records all generate data that must be managed. Unfortunately, it’s a data-driven world where most businesses struggle with dirty data, and many still can’t even perform basic deduplication or record linkage efficiently. When data is scattered across siloed systems with inconsistent formats, the result is often duplicate entries, missing information, and errors that ripple through operations. Packaging firms know this pain too well: duplicate records create confusion in customer and supplier databases, impede day-to-day efficiency, inflate storage costs, slow down processing, and introduce critical reporting errors.
So how can a packaging company turn this chaotic data situation around? The answer lies in modern data quality tools and practices – specifically, solutions like fuzzy data matching, robust data cleansing and profiling, project automation, and multi-user collaboration on a platform that integrates with all your data sources. In this blog, we’ll explore how a packaging business can benefit from these capabilities (using Match Data Pro as an example) to transform messy data into a trusted asset. We’ll mix in a few real-world flavored scenarios to illustrate the impact. Let’s dive in.
The Dirty Data Dilemma in Packaging Companies
Every packaging manufacturer, from plastics to corrugates, grapples with data coming from multiple directions. You might have ERP systems handling production, CRM databases for customer orders, procurement platforms for suppliers, and maybe spreadsheets flying around for everything in between. Without a unified approach, these systems end up with inconsistencies – a supplier’s name spelled three different ways, or the same customer entered twice under slight variations. Over time, this dirty data piles up. Business users often find themselves manually cleaning spreadsheets or cross-checking records, which is tedious and error-prone. In fact, approximately 65% of organizations still rely on manual methods (like spreadsheets) for data cleaning and deduplication – a statistic that underscores how common and unsustainable this practice is as data volumes explode.
Use case scenario: Imagine the procurement team at a packaging company preparing a spend report. They discover “PolyChem LLC” and “PolyChem, Inc.” in their vendor list – are those the same supplier? Manually investigating each instance across plant systems could take hours. It’s easy to miss one, leading to inaccurate spend totals and potential over-ordering from duplicate suppliers. This scenario highlights why an automated, intelligent approach to data quality is so essential.
Fuzzy Matching: Unifying Inconsistent Records
One of the most powerful techniques to tackle duplicate or inconsistent records is fuzzy data matching. Unlike exact matching (which would treat “PolyChem LLC” vs “PolyChem, Inc.” as completely different), fuzzy matching intelligently finds similarities and matches records even when names, codes, or addresses don’t perfectly line up. A modern data matching platform like Match Data Pro (MDP) uses advanced configurable fuzzy logic to handle these slight variations. MDP’s fuzzy matching module can accurately match, deduplicate, and group records – even when data contains inconsistencies, misspellings, or formatting differences. It lets you define match criteria and thresholds, so you can tailor how strict or lenient the matching should be for your needs. This is ideal for packaging businesses where data from different sources might use different abbreviations or formats (think “123 Main St.” vs “123 Main Street”, or a product code with dashes in one system and none in another).
For our hypothetical procurement example, fuzzy matching would automatically link “PolyChem LLC” with “PolyChem, Inc.” as the same entity, despite the minor naming discrepancy. The same goes for customer records: if a client “Global Beverages Co.” appears as “Global Beverage Company” elsewhere, a fuzzy match can catch it. By grouping these dupes together, you get a single source of truth for each supplier, customer, or product. This not only prevents confusion but also ensures consolidated reporting. As one data analyst put it, having reliable matching in place means “multiple data sets can be merged in a timely, trusted manner” – a critical capability when consolidating data from dozens of plants.
Data Cleansing and Profiling: Building a Strong Data Foundation
Of course, matching alone isn’t enough; you first need to clean and understand your data. This is where data cleansing and data profiling come in. Data profiling is like an initial diagnostic – it helps you inspect the health of your data before you operate. An effective profiling tool will reveal patterns, anomalies, and statistics about your dataset. For example, it can show that a “State” field has 5% blanks or that there are 20 different formats for phone numbers in your contact list. MDP’s data profiling feature offers 25+ key metrics to thoroughly analyze data quality and uncover issues. With profiling, a packaging company can quickly spot if, say, some product dimension fields contain outlier values or if certain customer entries lack tax IDs. It’s essentially a health check that guides your cleansing efforts to where they’re needed most.
After profiling, data cleansing takes center stage. Cleansing involves standardizing and correcting the data so that it meets quality standards and business rules. Think of tasks like removing extra whitespace, fixing typos, converting all unit measurements to a standard format, or enriching data with consistent codes. The goal is to eliminate errors and inconsistencies so that your data is analysis-ready. Modern cleansing tools make this easier than ever. For instance, MDP provides over 30 customizable options to clean and standardize your data. You can replace values (e.g., convert all “N/A” to blanks), enforce patterns (like proper casing for names), or validate fields (ensure every SKU follows the proper format). The interface is completely point-and-click, meaning you don’t have to be a programmer to tidy up your tables.
Use case scenario: The quality control department at a packaging firm might use data cleansing to standardize how plant locations are recorded in different systems. One system might use plant codes (“PLT-1001”), while another uses names (“Plant 1001 – Dallas”). With the dictionary feature, they can create a rule to map or rename these to a consistent format. Meanwhile, profiling might have revealed some products with dimensions recorded in mixed units (inches vs centimeters). A quick cleansing rule can convert all units to, say, centimeters, ensuring an apples-to-apples comparison of product specs. By saying goodbye to data errors and inconsistencies through powerful cleansing tools, the company significantly reduces miscommunications and mistakes that stem from messy data.
Project Automation: Streamlining Data Workflows
Once you have matching rules and cleansing steps defined, wouldn’t it be nice to run them automatically on a schedule or with minimal effort each time your data updates? This is where project automation in a platform like MDP proves invaluable. Automation allows you to configure end-to-end data workflows – from import, to cleansing, matching, and export – and then execute them without manual intervention. In today’s fast-paced environment, packaging companies benefit hugely from this capability. You can set up scheduled runs to refresh and process your data, say, every night or every week, ensuring that new entries (new customers, new orders, etc.) get cleaned and matched as they come in. If a particular data pipeline needs to run after an external event (like after the ERP updates inventory at midnight), you can even trigger MDP jobs via API calls to integrate seamlessly with your IT ecosystem.
What does this mean in practice? Imagine the sales team gets a daily feed of new leads or orders from an e-commerce site. Rather than someone manually downloading that file, merging it into a master list, cleaning duplicates, and then emailing reports every morning, MDP’s project automation can handle it hands-free. Step 1: Import the new data (from a database or file) into the project. Step 2: Automatically apply cleansing rules (standardize product codes, verify addresses). Step 3: Apply fuzzy matching definitions to link any existing customer entries or identify duplicates. Step 4: Export the updated master customer list or a summary report to the desired location (like a database, CRM, or even a simple Excel file). Once set up, this pipeline can run at 2 AM every day, so by the time the team gets into the office, they have an up-to-date, de-duplicated, clean dataset waiting for them. No more scrambling with VLOOKUPs or manual merges! It’s not just about convenience – it ensures consistency. Automated processes run the same way every time, reducing the risk of human error and freeing up your analysts to focus on value-added analysis instead of repetitive chores.
Multi-User Collaboration: Data Quality as a Team Sport
Data quality improvement isn’t a solo job – it involves collaboration between IT, analysts, business users, and sometimes external partners. Packaging companies often have distributed teams: maybe a central data team at headquarters and local data stewards at each plant. Multi-user project collaboration ensures everyone can work together on the same platform without stepping on each other’s toes. MDP is designed to support exactly this kind of teamwork. Whether you’re cleansing, profiling, enriching, or deduplicating data, MDP supports secure multi-user collaboration and process automation across teamsmatchdatapro.com. In practice, this means you can have role-based access control, so each team member gets the appropriate permissions. For example, a data engineer could set up the initial project and connectors, a business analyst could design the matching rules and cleansing steps, and a department manager could review the results – all within the same project environment.

Collaboration is key: With multi-user access, different team members (from IT, data analysts, to business stakeholders) can contribute to data projects together in one platform.
Teams can also leverage features like versioning and audit trails to keep track of changes. If someone tweaks a matching rule or updates a cleansing standard, the changes can be logged. This is especially important for packaging companies operating in regulated environments (think food and beverage packaging, where data accuracy might tie into compliance reporting). Enterprise-grade user management tools allow admins to manage who sees what – for instance, segregating projects by department or region, and implementing approvals for certain actions. Collaboration isn’t just internal, either; perhaps you want a trusted supplier to upload data directly into your project or have a consultant review your setup – having a flexible multi-user system makes this possible while still keeping data security intact (through features like IP/country restrictions and multi-factor authentication as needed).
The bottom line is that when data quality becomes a shared responsibility, it vastly improves. People closest to the data can fix issues at the source, and the organization collectively benefits from cleaner, more reliable information. MDP’s collaborative features recognize that reality and make it easy for organizations to manage data across teams, systems, and workflows in a secure environment.
Seamless Integration: Connect to Any Data Source
(and Bring Your SQL)
A big part of the data chaos in packaging companies comes from having many different data sources. You might have an Oracle or SAP database for ERP, SQL Server for some legacy systems, a new PostgreSQL database for a cloud application, plus countless Excel/CSV files exchanged with partners. It’s critical that your data quality solution can connect to any database or file format you throw at it. Match Data Pro shines here with a broad range of import/export connectors. It supports everything from popular relational databases like MySQL, SQL Server, and PostgreSQL to NoSQL databases (MongoDB) and even cloud storage like Google Drive, Dropbox, OneDrive. Need to pull data from Snowflake or via a JSON API? It can handle that too. In short, you can bring all your data into one place for cleaning and matching, regardless of where it lives.
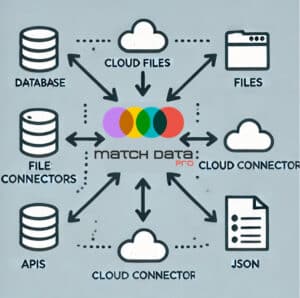
MDP acts as a central hub for your data: it connects to databases, files, cloud storage, and APIs, bringing disparate data sources together for cleansing and matching.
Setting up these connections is typically straightforward. You enter the credentials for your database (host, username, password, etc.) and you have the option to save those credentials securely for reuse. This is a big time-saver for recurring tasks; for example, if you frequently connect to your production SQL database, you don’t want to re-enter the connection info each time. With saved connections, MDP will simply use the stored (encrypted) credentials whenever the project runs, and you can update them easily if a password or connection string changes. Once connected, you can either select the tables you need or, even more powerfully, write a custom SQL query to fetch exactly the data you want. This means you can join tables, filter data, or select specific columns within the database before it even comes into the tool. For instance, you might only need the last 2 years of order data from a 10-year archive – a custom SQL query can pull just that subset, making your project more efficient. And if it’s a query you’ll run often, you can save it within MDP for future use, much like saving a view or stored procedure, but without needing DBA privileges on the source system.
Use case scenario: Suppose our packaging company wants to merge customer data from two systems: an old CRM database and a new e-commerce platform. With MDP, they set up connectors to both the SQL Server CRM and the MySQL e-com database. For the CRM, they use a custom SQL query to select only active customers and their latest contact info. For the e-com, they maybe pull all accounts created in the last 5 years. Both datasets flow into MDP’s project. From there, fuzzy matching links any overlapping customers (e.g., if some customers exist in both systems under slightly different names), and the team can merge them to create a unified customer master list. Finally, the cleaned, unified data can be exported back to a target of choice – perhaps uploaded to a cloud data warehouse or simply downloaded as an Excel file for the sales team. All of this happens in one tool, without the need to manually juggle files or write complex scripts to reconcile the two sources. Connectors and integration capabilities ensure that bringing data into the platform (and sending it out) is seamless and versatile, which is crucial for any large business dealing with heterogeneous data systems.
Conclusion: Turning Data Chaos into Clarity
In the fast-moving world of packaging manufacturing, having clean, consistent, and accessible data is no longer a luxury – it’s a necessity for staying competitive and responsive to customer needs. We’ve seen how a company like Graham Packaging could benefit by implementing a solution such as Match Data Pro to get their data house in order. By using fuzzy matching to unify records, data cleansing and profiling to boost accuracy, project automation to save time, and collaborative tools to engage the whole team, what was once messy data transforms into a reliable foundation for decision-making. The benefits go straight to the bottom line: fewer errors in orders and shipments, more effective marketing (since duplicate or outdated contacts are eliminated), and streamlined operations because everyone is referencing the same “single version of truth.”
Crucially, these improvements also set the stage for advanced initiatives. It’s hard to embark on AI or analytics projects when your data is full of holes and duplicates – but once you’ve cleaned things up, you can trust the insights that tools generate. Many packaging businesses are eager to leverage predictive analytics (for maintenance, supply chain optimization, etc.) or improve customer experiences. Clean data is the launchpad for those efforts. As one industry report noted, messy, duplicated data has evolved into a full-blown crisis that threatens digital transformation goals. The flip side is that by addressing data quality head-on, you remove a major roadblock to innovation.
In summary, investing in a robust data matching and cleansing platform is an investment in efficiency, accuracy, and future growth. It lets your team focus on what they do best – delivering quality packaging solutions – without being bogged down by spreadsheet gymnastics and manual cleanup. The result is a more data-driven organization that can make smarter decisions quickly. For any packaging company drowning in data chaos, tools like Match Data Pro can be the life raft that brings order, collaboration, and confidence back to their data. And once you experience the ease of clean, matched, and readily available information , you’ll wonder how you ever lived without it. Here’s to turning data chaos into clarity, one fuzzy match at a time! Register Now!