






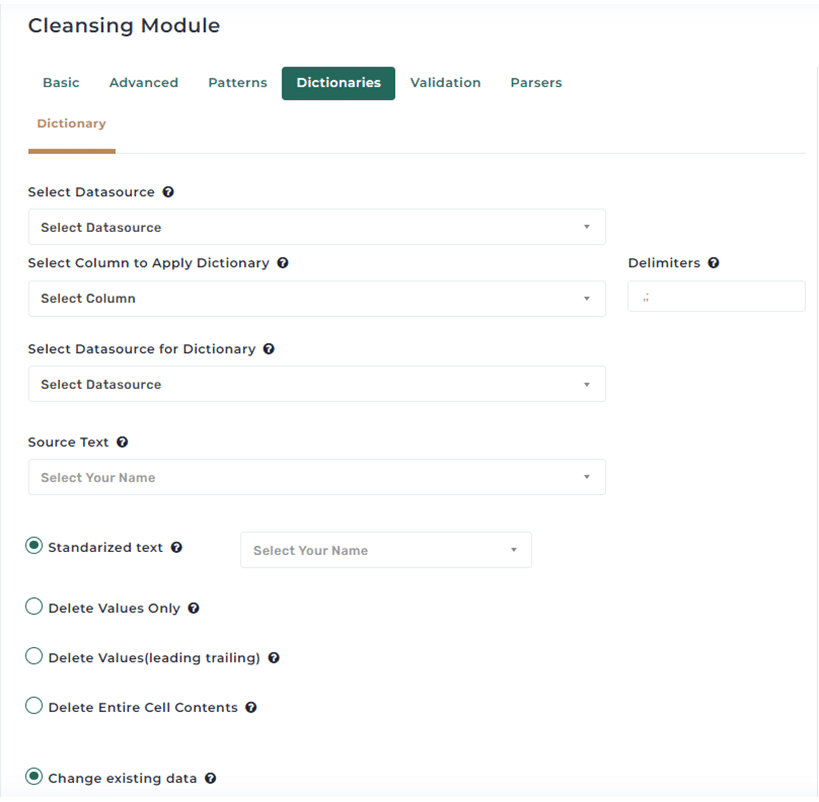
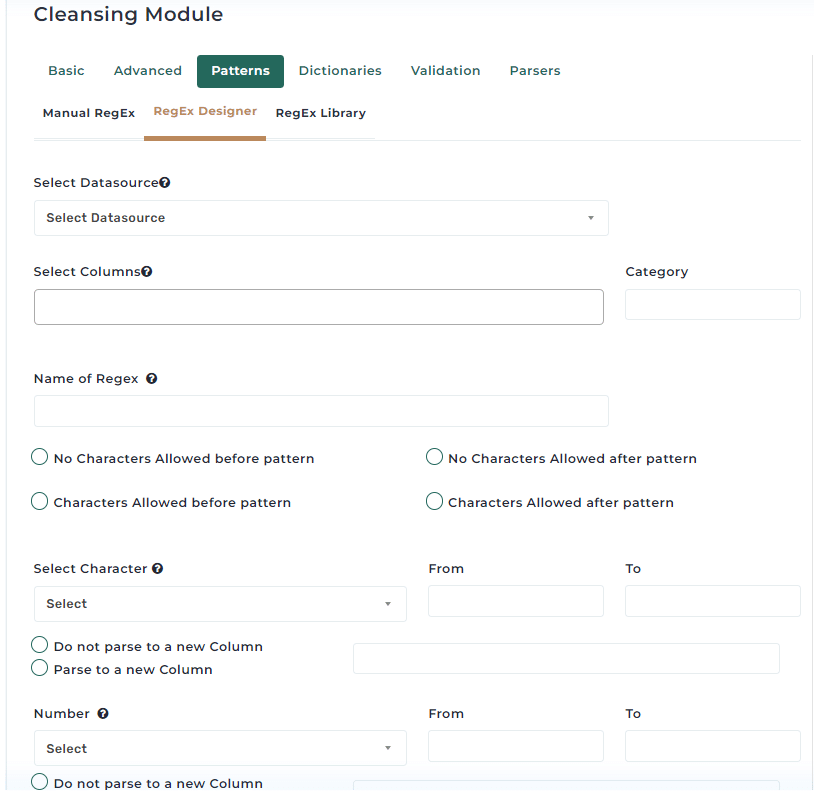
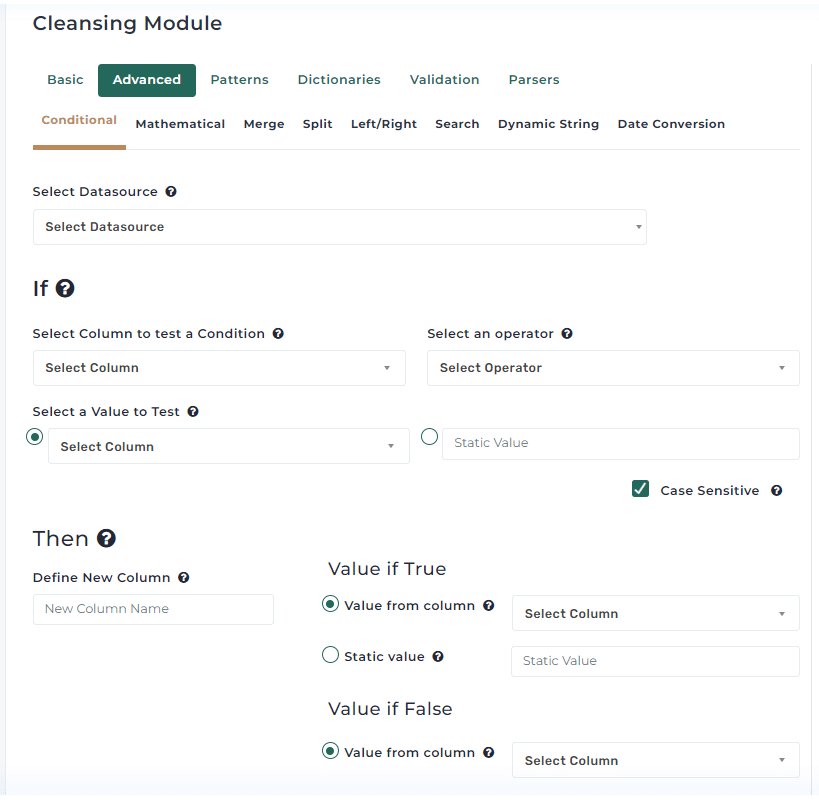
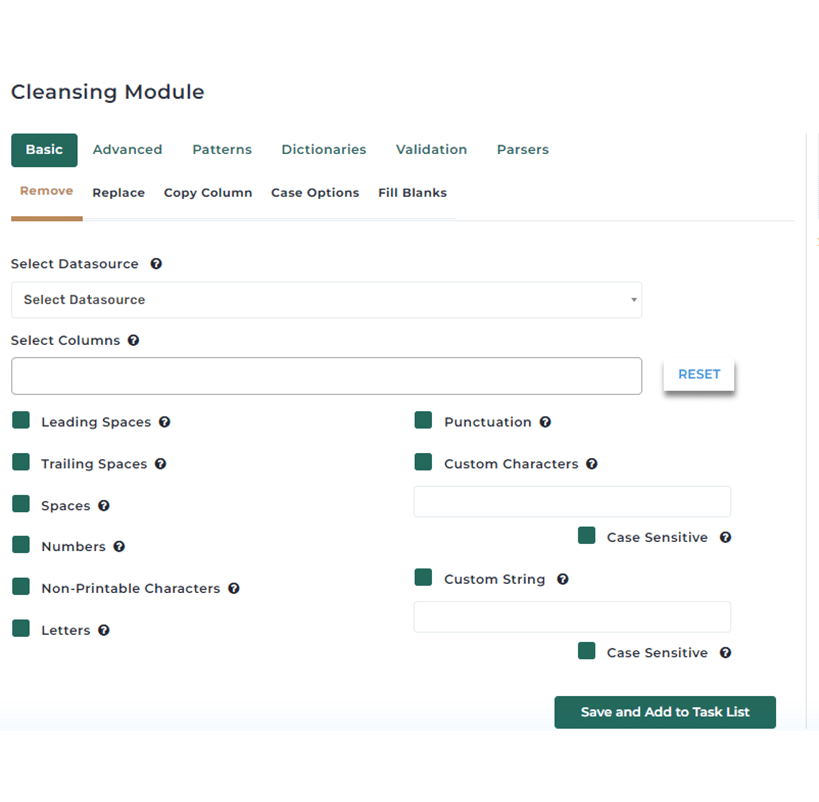





Address Matching Explained:
Resident, Household & Individual Matching
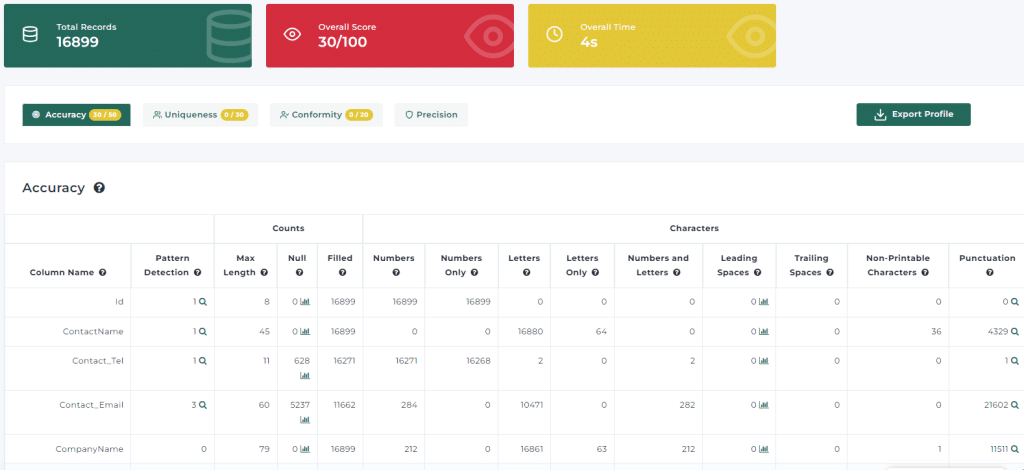
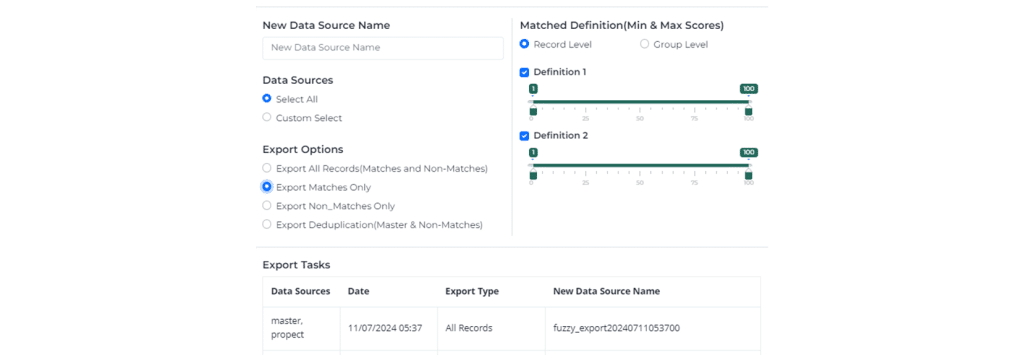
Address Matching Explained:Resident, Household & Individual Matching Why Address Matching Fails More Often Than People Realize Address matching sounds simple.…

The Ultimate Guide to Data Matching and Merging
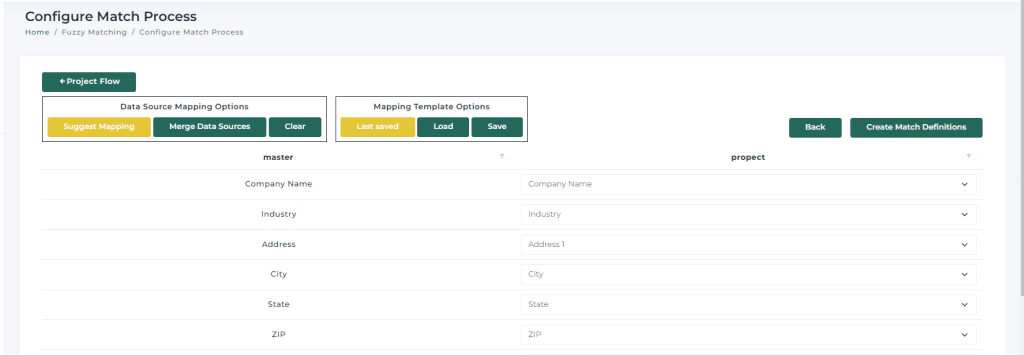
The Ultimate Guide to Data Matching and Merging in 2025 Matching and merging data is at the heart of every…

What Is Data Matching? A Simple Guide with Examples
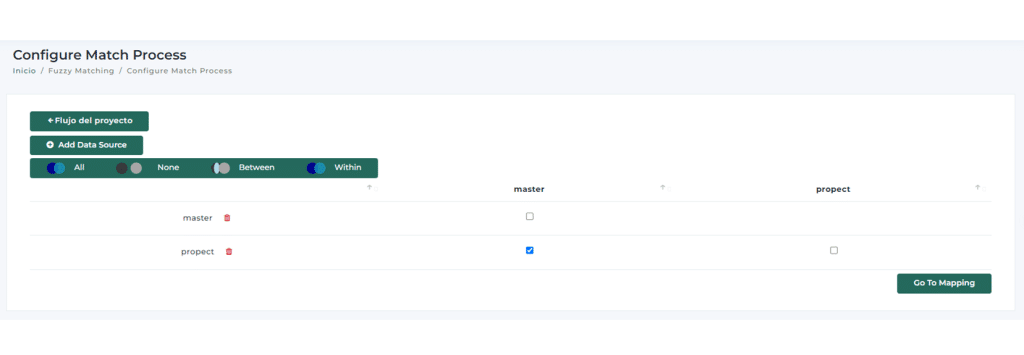
What Is Data Matching? A Simple Guide WithReal Examples Data matching is the process of identifying and linking records that…