
Data matching software identifies and links records that represent the same real-world entity across disparate datasets — even when names, addresses, or identifiers are inconsistently formatted or partially missing. Choosing the wrong tool means persistent duplicates, failed entity resolution, and broken downstream analytics. This guide gives data engineers, CDOs, and RevOps leaders a concrete framework for evaluating and selecting the right platform in 2026.
What Is Data Matching Software — and Why Does the Category Matter?
Data matching software is a category of data quality tooling specifically designed to compare records across one or more datasets and determine whether two or more records refer to the same entity. That entity might be a customer, a company, an address, a product SKU, or any other identifiable object your organisation tracks.
The category matters because raw data is rarely clean. In a typical enterprise environment, the same customer might appear as “IBM Corp” in a CRM, “IBM Corporation” in an ERP, and “I.B.M.” in a legacy billing system. A general-purpose ETL tool will treat these as three distinct organisations. Dedicated data matching software — particularly tools that support fuzzy matching, probabilistic scoring, and entity resolution — will recognise them as one.
According to IBM, a data quality platform is “a software solution designed to help organizations manage, maintain, and improve the quality of their data” — and record matching is one of the most critical capabilities within that broader function.
Exact Match vs. Fuzzy Match vs. Entity Resolution
Before evaluating any tool, understand which matching paradigm your use case requires:
- Exact match: Deterministic, field-by-field comparison. Fast and accurate when data is well-governed. Fails on any formatting variation.
- Fuzzy match: Algorithmic similarity scoring (Levenshtein distance, Jaro-Winkler, Soundex, n-gram). Handles typos, abbreviations, and minor variations. Requires threshold tuning.
- Probabilistic / ML matching: Assigns weighted confidence scores across multiple fields simultaneously. Better precision on noisy, multi-source datasets at scale.
- Entity resolution: Builds persistent identity graphs that link records across systems over time. Best for master data management (MDM) and 360-degree customer views.
Most production data matching workflows require a combination of all four — which is why a configurable, multi-algorithm platform outperforms single-method tools.
Core Features to Require in Any Data Matching Software Evaluation
Not all tools that advertise “data matching” deliver the same depth of capability. Use this checklist as a minimum bar when shortlisting vendors:
- Configurable match algorithms: The ability to choose and combine Levenshtein, Jaro-Winkler, Soundex, exact, and phonetic algorithms per field — not a single black-box score.
- Multi-field weighted scoring: Match confidence should be computed across name, address, phone, email, and identifier fields simultaneously, with user-defined field weights.
- AI-assisted match suggestions: Machine learning that learns from reviewer decisions to surface high-confidence matches and suppress false positives over time.
- Entity resolution / identity graph: Cross-dataset linking that persists across batch runs and streaming updates — not just a one-time deduplication job.
- Address verification: CASS-certified address standardisation integrated into the match pipeline so addresses are normalised before comparison.
- Deduplication: Within-dataset duplicate detection with configurable survivorship rules to determine which record version to retain.
- Merge & survivorship: Automated or rules-based merging of matched record pairs into a single best-record, preserving audit lineage.
- API access: A live fuzzy search API for real-time matching at the point of data entry — not just batch processing.
- Import / export connectors: Native connectivity to CRMs (Salesforce, HubSpot), ERPs, data warehouses, and flat files without custom ETL code.
- Job automation & scheduling: Ability to run matching pipelines on a schedule or trigger-based cadence, with logging and alerting.
- On-premise / private cloud deployment: For regulated industries (healthcare, finance, government) where data cannot leave the firewall.
The Data Matching Software Pipeline: From Raw Records to Master Data
Understanding the end-to-end pipeline helps you map tool capabilities to the stages where your data quality breaks down. Here is the standard flow used by production data matching deployments:
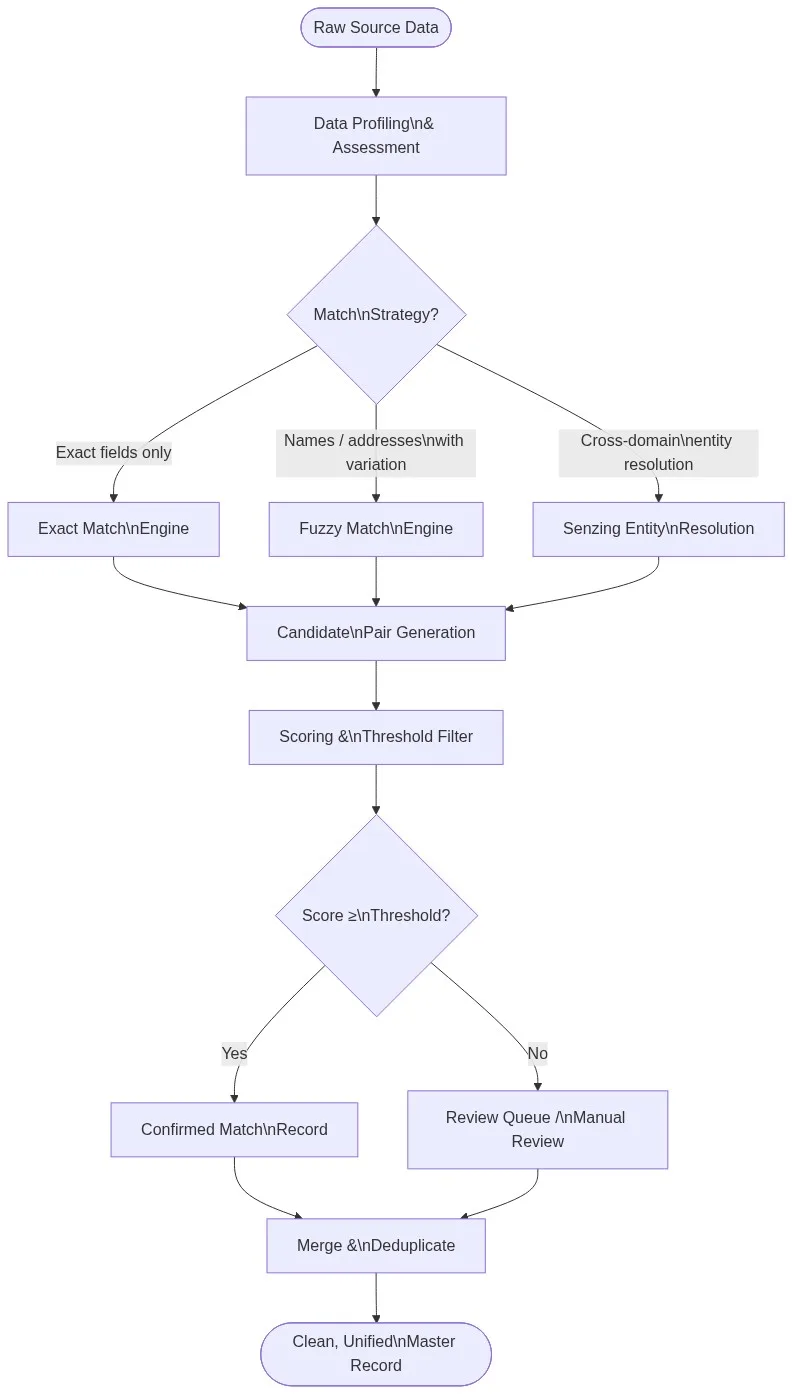
Stage 1: Data Profiling and Assessment
Before matching, you need to understand what you have. AI-powered data profiling scans every column for completeness, cardinality, format consistency, and null rates. This tells you which fields are reliable enough to match on and which need standardisation first. For a 500,000-record CRM export, profiling might reveal that the “Company Name” field has 12 distinct casing patterns and that 8% of phone numbers are missing area codes — critical intelligence that shapes algorithm selection.
Stage 2: Pre-Match Standardisation
Before any similarity scoring begins, address fields should be parsed and CASS-verified, names should be normalised (title case, suffix removal), phone numbers should be formatted to E.164, and identifiers (EIN, DUNS, NPI) should be validated against reference data. Tools that skip this step produce match scores that reflect formatting differences, not genuine record divergence.
Stage 3: Candidate Pair Generation (Blocking)
Comparing every record against every other record in a million-row dataset is computationally prohibitive — O(n²) complexity. Production-grade matching software uses blocking (or indexing) to reduce the candidate set: only records sharing at least one blocking key (e.g., same first 3 characters of surname AND same ZIP prefix) are compared in detail. This cuts comparison cycles by orders of magnitude without sacrificing recall.
Stage 4: Scoring and Threshold Filtering
Each candidate pair is scored across configured fields. A well-tuned production rule might weight company name at 40%, address at 30%, phone at 20%, and email at 10%. Pairs scoring above the accept threshold (e.g., 0.85) are auto-confirmed as matches; pairs below a reject threshold (e.g., 0.50) are auto-dismissed; pairs in the middle go to a human review queue. This tiered approach maximises throughput while preserving precision on ambiguous records.
Stage 5: Entity Resolution and Merging
Confirmed match pairs are fed into an entity resolution layer — such as Senzing — that builds and maintains a persistent identity graph. When a new record arrives next month, the graph already knows “IBM Corp” and “IBM Corporation” are the same node and links the new record accordingly without re-running the full pipeline. Merging logic then selects the surviving field values based on configurable survivorship rules (most recent, most complete, highest-trust source).
Data Matching Software Comparison: Key Platforms Evaluated
The following table evaluates the major platforms data engineers encounter when shortlisting data matching software. Scores reflect publicly available feature documentation and independent analyst assessments as of 2026.
| Platform | Coincidencia difusa | Resolución de entidad | Address Verification | Live API | On-Premise | No-Contract SaaS | Free Trial |
|---|---|---|---|---|---|---|---|
| Datos de partidos Pro | ✅ Configurable multi-algorithm | ✅ Senzing-powered | ✅ CASS-certified | ✅ Live fuzzy search API | ✅ | ✅ Monthly, no lock-in | ✅ Instant |
| Informatica IDQ | ✅ Advanced | ✅ MDM add-on | ✅ Via add-on | ⚠️ Limitada | ✅ | ❌ Annual contract | ❌ |
| IBM QualityStage | ✅ Probabilistic | ✅ MDM suite | ✅ | ⚠️ Via DataStage | ✅ | ❌ Enterprise contract | ❌ |
| Talend Data Quality | ⚠️ Básico | ❌ Not native | ⚠️ Via connector | ⚠️ Via pipeline | ✅ | ❌ Subscription | ⚠️ Limitada |
| WinPure | ✅ Configurable | ❌ Not native | ✅ CASS | ❌ | ✅ | ⚠️ Annual | ✅ |
| OpenRefine | ⚠️ Basic clustering | ❌ | ❌ | ❌ | ✅ Open source | ✅ Free | ✅ |
✅ = Full native capability ⚠️ = Partial / requires add-on ❌ = Not available or not confirmed
Evaluation Criteria: How to Score Vendors Against Your Requirements
A structured evaluation prevents vendor demos from substituting for technical due diligence. Use this scoring framework when issuing an RFP or running a proof of concept (POC):
1. Match Accuracy on Your Own Data
Never evaluate match accuracy on a vendor’s curated demo dataset. Bring a representative 50,000-record sample from your own environment — ideally one where you already know the ground-truth matches — and measure precision (what fraction of confirmed matches are correct) and recall (what fraction of true matches were found). A tool scoring 94% precision and 89% recall on vendor data but 71% precision on your data is not a 94% tool for your use case.
2. Configurability and Algorithm Transparency
Ask the vendor to show you exactly which algorithm is applied to each field and how match scores are computed. Black-box AI matching that cannot be explained or tuned is a governance and auditability liability, particularly in regulated industries. You need to be able to justify why two records were merged to a data steward, a regulator, or an internal audit team.
3. Scale and Performance Benchmarks
Request documented throughput benchmarks for your approximate data volume. For 10 million records, how long does a full deduplication run take? What is the latency of a single-record real-time API lookup? Can the job be parallelised? Does performance degrade linearly or exponentially as volume grows?
4. Deployment Flexibility
If your data governance policy requires on-premise or private cloud deployment — common in healthcare (HIPAA), financial services, and government — confirm this is a first-class deployment path, not an afterthought. Some SaaS-first vendors support on-premise in name only, with degraded feature sets or unsupported configurations.
5. Total Cost of Ownership (TCO)
Headline licensing costs rarely tell the full story. Factor in: implementation services, data connector licensing, training, annual support contracts, infrastructure costs (for on-premise), and the engineering time required to build and maintain custom integrations. A lower-priced platform that requires 200 hours of professional services per year to maintain may cost more than a higher-priced platform with native connectors and job automation.
Common Data Matching Pitfalls — and How Purpose-Built Software Avoids Them
Teams that build homegrown matching logic using SQL, Python (pandas, FuzzyWuzzy), or basic ETL transformations consistently encounter the same failure modes at scale:
- The 1-field match trap: Matching on company name alone without address or phone correlation produces both false positives (two different “ABC Corp” entities merged) and false negatives (the same entity under two name variants missed entirely).
- Threshold mistuning: Setting a match threshold too low floods the review queue with obvious non-matches; too high, and legitimate duplicates pass through undetected. Purpose-built software exposes precision-recall curves so you can set thresholds with empirical justification.
- No survivorship logic: Matching identifies duplicates; survivorship decides which record version wins. Without a survivorship strategy, merged records silently inherit stale or incorrect field values from the less-reliable source record.
- Batch-only processing: A nightly deduplication job creates a 24-hour window where new duplicates enter your CRM unchecked. A live fuzzy search API catches duplicates at the point of entry before they are persisted.
- No entity persistence: Running a new deduplication job from scratch each month rather than maintaining a persistent entity graph means previously resolved identities must be re-discovered every cycle — wasted compute and inconsistent results.
For a technical deep-dive into why algorithmic approaches break down and how AI-powered matching fixes the gaps, read our guide: Why AI Data Matching Fails in 2026 — And How to Fix It.
Match Data Pro: Built for Production Data Matching at Every Scale
Match Data Pro is a purpose-built data quality platform that covers the full matching and deduplication lifecycle — from AI data profiling through configurable fuzzy matching, Senzing entity resolution, CASS address verification, and automated job pipelines. It is available as a no-contract monthly SaaS or on-premise deployment, with a live fuzzy search API for real-time matching at the point of entry.
Key differentiators for teams evaluating data matching software:
- Configurable fuzzy algorithms: Choose from Levenshtein, Jaro-Winkler, Soundex, n-gram, exact, and phonetic algorithms per field — not a single locked-in approach.
- Senzing entity resolution: Production-grade identity graph that persists entity relationships across batch runs and real-time updates. See how it works: How to Achieve Accurate Senzing Entity Resolution in 2026.
- AI match suggestions: The platform learns from reviewer decisions and surfaces high-confidence candidate pairs automatically, reducing manual review time.
- CASS address verification: USPS-certified address standardisation integrated into the match pipeline. Read more: How to Cleanse and Standardize Address Data.
- Live fuzzy search API: Match incoming records at point of entry against your master dataset in under 200ms.
- No-contract SaaS: Monthly billing, instant provisioning, no implementation engagement required to get started.
- On-premise / private cloud: Full-feature deployment for regulated data environments.
For a broader look at how matching fits into the full data quality lifecycle, see: Data Matching & Merging: Complete 2026 Guide and What Is Data Matching? Guide with Real Examples.
Need to match across multiple fields simultaneously? Our technical walkthrough covers the mechanics: What’s the Best Way to Match Data Across Multiple Fields?.
If you are evaluating broader data cleansing capabilities alongside matching, see our 2026 ranked comparison: Best Data Cleansing Tools 2026: Ranked & Compared.
Frequently Asked Questions: Data Matching Software
What is data matching software used for?
Data matching software is used to identify, link, and deduplicate records that refer to the same real-world entity across one or more datasets. Common use cases include CRM deduplication, MDM (master data management), customer 360 consolidation, address verification, fraud detection, regulatory reporting, and data migration quality assurance. The software applies exact, fuzzy, probabilistic, or entity resolution techniques depending on the nature and quality of the source data.
What is the difference between fuzzy matching and exact matching in data software?
Exact matching compares field values character-by-character and only confirms a match when the values are identical (or match after basic normalisation). It is fast and precise but fails on any formatting variation — a single extra space, abbreviation, or typo produces a non-match. Fuzzy matching applies similarity algorithms (Levenshtein distance, Jaro-Winkler, Soundex) to score how similar two field values are on a scale from 0 to 1, then applies a configurable threshold to determine a match. It is more tolerant of real-world data variation and is the appropriate default for names, addresses, and free-text fields.
How do I choose the best data matching software for my organisation?
Evaluate vendors against five criteria: (1) match accuracy on your own data in a POC, not a vendor demo dataset; (2) algorithm configurability and score transparency; (3) throughput benchmarks at your data volume; (4) deployment options that meet your governance requirements (SaaS, on-premise, private cloud); and (5) total cost of ownership including implementation, connectors, and ongoing maintenance. Require a free trial and bring a labelled test dataset where ground-truth matches are already known.
Can data matching software handle real-time matching, or is it batch-only?
Many legacy data matching tools are batch-only — they run nightly or weekly jobs against a static dataset. Modern platforms including Match Data Pro offer a live fuzzy search API that matches incoming records against a master dataset in real time, typically in under 200 milliseconds. Real-time matching is critical for CRM duplicate prevention at point of entry, fraud screening, and onboarding workflows where a 24-hour lag is unacceptable.
What is entity resolution and how is it different from deduplication?
Deduplication removes duplicate records within a single dataset — identifying that two rows in the same CRM table represent the same customer and merging them. Entity resolution is broader: it builds and maintains a persistent identity graph that links records across multiple systems, datasets, and time periods. When a new record arrives, entity resolution checks it against the existing identity graph rather than re-running a full deduplication pass. Senzing is the leading entity resolution engine for production deployments, and it is natively integrated into the Match Data Pro platform.
Start Matching with Confidence — Free Trial Available
Match Data Pro gives data engineering teams and data leaders a production-grade matching platform with no implementation backlog, no annual contract, and no black-box algorithms. Bring your own data, configure your match rules, and see results in the same session.
- Start your free trial → No contract. No credit card required to explore.
- Book a technical demo: Talk to a data quality engineer about your specific matching use case. Email sales@matchdatapro.com or contact us here.
Already using a homegrown matching approach and hitting accuracy or scale limits? Our team can run a rapid POC against your data and deliver a benchmark report within 48 hours. Reach out to sales@matchdatapro.com.