

Data cleansing is the systematic process of identifying and correcting inaccurate, incomplete, duplicate, and improperly formatted records within a dataset before it is used for analytics, machine learning, or operational workflows. Without a disciplined cleansing pipeline, even well-architected data platforms will produce unreliable outputs — because no algorithm, no model, and no dashboard can compensate for the garbage that enters it.
According to a 2026 IBM Institute for Business Value report, over a quarter of organisations estimate they lose more than USD 5 million annually due to poor data quality — with 7% reporting losses exceeding USD 25 million. For data engineers, CDOs, and RevOps leaders, that figure reframes data cleansing from a maintenance task to a core business function.
This guide covers the complete data cleansing pipeline, the techniques that matter most at scale, a comparison of tooling approaches, and how to operationalise cleansing as a repeatable, automated process inside your data infrastructure.
What Is Data Cleansing? Definitions and Scope
Data cleansing — also called data scrubbing or data cleaning — refers to the detection and remediation of quality defects across one or more datasets. The scope is broader than many teams initially assume. It is not simply removing blank rows from a spreadsheet. A production-grade cleansing pipeline typically addresses the following defect classes:
- Duplicate records: Two or more rows representing the same real-world entity — a customer, a company, a transaction — that have entered the system through separate ingestion paths or manual entry errors.
- Structural inconsistencies: Fields formatted differently across records or sources (e.g.,
2024-01-15vs.15/01/2024vs.Jan 15 2024). - Invalid values: Entries that fail domain rules — a phone number with 14 digits, a US ZIP code of
00000, an email address without an@symbol. - Null and missing fields: Mandatory fields left empty, or placeholder values such as
N/A,999, orNULLthat are semantically meaningless. - Referential integrity violations: Foreign keys referencing records that no longer exist, or join keys that are mismatched across tables.
- Stale or outdated data: Records whose values were once accurate but have since changed — moved addresses, changed company names, superseded product codes.
Each defect class requires a different remediation technique, which is why ad hoc scripts rarely scale. A systematic, pipeline-driven approach is the only sustainable solution at enterprise data volumes.
The 6-Stage Data Cleansing Pipeline
Professional data cleansing is not a single operation — it is an ordered sequence of stages, each building on the last. The diagram below illustrates the end-to-end flow from raw ingested data to a trusted golden record.
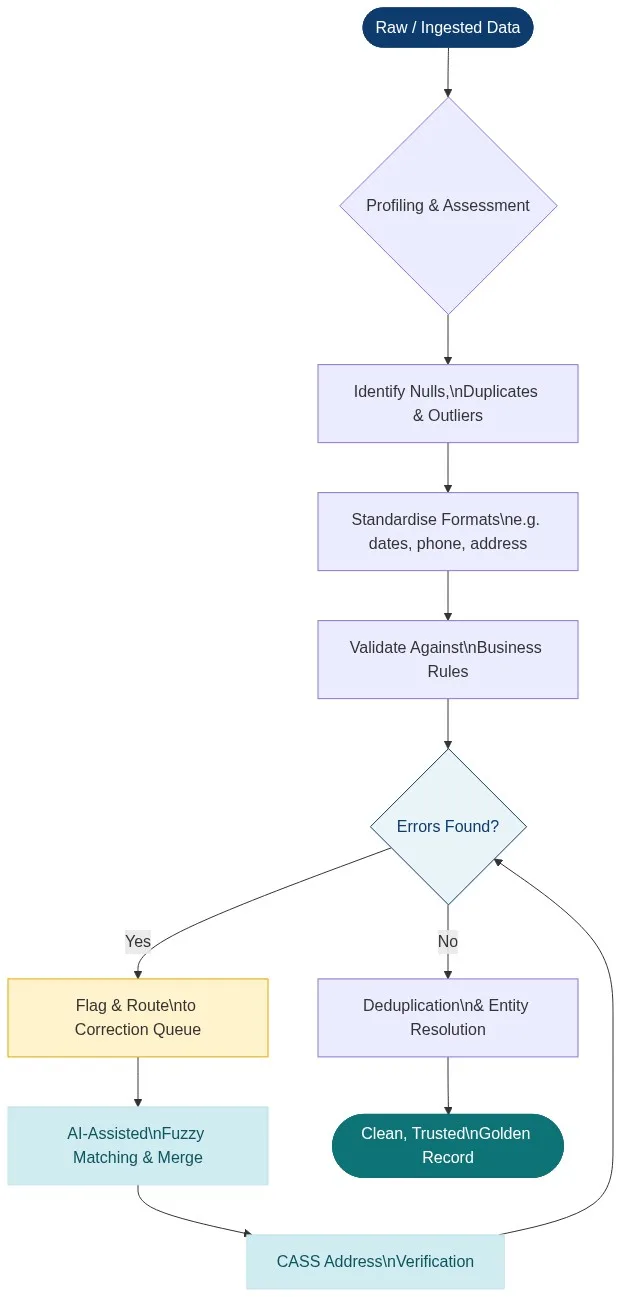
Stage 1: Data Profiling and Assessment
Before a single record is modified, the data must be profiled. Profiling generates statistical summaries — null rates, cardinality, value distributions, format patterns — across every column. This baseline tells you what you are dealing with: which fields have 40% null rates, which columns have unexpected data types, and where duplicate keys cluster. Match Data Pro’s AI Data Profiling module automates this assessment, surfacing anomalies and generating quality scores before any cleansing work begins.
Stage 2: Standardisation
Standardisation transforms free-form or inconsistently formatted data into a canonical representation. Common standardisation operations include:
- Normalising date formats to ISO 8601 (
YYYY-MM-DD) - Uppercasing or title-casing name fields consistently
- Stripping country codes and formatting phone numbers to E.164
- Expanding address abbreviations (
St→Street,Blvd→Boulevard) - Converting currency fields to a single base currency with consistent decimal precision
Standardisation is a prerequisite for matching. Two records cannot be reliably compared if one stores United States and the other stores US o USA.
Stage 3: Validation Against Business Rules
Validation checks that each field value is not just present, but correct according to domain logic. Rules are either generic (email format, phone length) or business-specific (account numbers must match a 10-digit pattern, product codes must exist in the master catalogue). Records that fail validation are flagged and routed to a correction queue — they are not silently dropped, which would introduce its own quality problem.
Stage 4: Fuzzy Matching and AI-Assisted Correction
Most real-world defects are not binary errors — they are near-misses. Jon Smith and Jonathan Smyth may well be the same person. Acme Corp. and ACME Corporation almost certainly are. Exact-match logic fails here. Fuzzy matching algorithms — Levenshtein distance, Jaro-Winkler, phonetic encodings like Soundex and Metaphone — compute similarity scores between field pairs and surface probable duplicates for review or automated merging. Match Data Pro’s configurable fuzzy matching engine supports multi-field weighted matching across names, addresses, phone numbers, and custom identifiers simultaneously.
Stage 5: Address Verification (CASS)
Address data is among the most error-prone in any CRM or database. CASS (Coding Accuracy Support System) certification is the USPS standard for address standardisation and deliverability verification. A CASS-certified process parses, corrects, and appends ZIP+4 codes to every US address, dramatically reducing undeliverable mail and improving geographic segmentation accuracy. Match Data Pro includes CASS address verification natively — no third-party connector required. Learn more in our guide to cleansing and standardising address data.
Stage 6: Deduplication and Entity Resolution
The final stage collapses identified duplicate records into a single authoritative golden record. For simple use cases, this is a merge operation governed by survivorship rules (e.g., most recently updated field wins). For complex, multi-source entity resolution — where the same company appears in a CRM, an ERP, a billing system, and an external enrichment feed under four different names — probabilistic entity resolution engines are required. Match Data Pro integrates Senzing entity resolution, the industry’s leading graph-based resolution engine, to handle large-scale, multi-source identity reconciliation with audit-grade lineage.
Data Cleansing Techniques Compared
Not all cleansing approaches are equal in accuracy, scalability, or maintainability. The table below compares the four most common approaches data engineering teams deploy:
| Approach | Lo mejor para | Escalabilidad | Handles Fuzzy Errors? | Maintainability |
|---|---|---|---|---|
| Manual review / spreadsheets | <10k records, one-off projects | ❌ Very low | ❌ No | ❌ Poor |
| Custom SQL / Python scripts | Structured, rules-based defects | ⚠️ Medium | ⚠️ Limitada | ⚠️ High dev overhead |
| Open-source tools (OpenRefine) | Small–medium ad hoc projects | ⚠️ Medium | ⚠️ Básico | ⚠️ No automation |
| AI-powered platform (Match Data Pro) | Enterprise, multi-source, recurring | ✅ Millions of records | ✅ Full fuzzy + entity resolution | ✅ Automated job scheduling |
For teams managing CRM data, marketing databases, or operational records at scale, the manual and script-based approaches collapse under volume and variety. The key differentiator for enterprise deployments is handling fuzzy errors at speed — the class of defect that no regex rule can catch.
Data Cleansing in Practice: A CRM Deduplication Workflow
To make this concrete, consider a RevOps team inheriting a Salesforce export of 850,000 contact records from a CRM consolidation project. The raw file contains records ingested from three legacy systems over eight years. The team’s goals: eliminate duplicates, standardise contact fields, verify addresses, and produce a single clean file for reimport.
Step 1 — Profile the dataset
AI profiling reveals: 22% of email fields are null or malformed, 31% of phone numbers are inconsistently formatted, 14% of records share a first + last name with at least one other record, and the company_name field has 4,200 distinct values that cluster into approximately 3,100 unique companies when fuzzy-grouped.
Step 2 — Standardise fields
Phone numbers are normalised to E.164 format. Company names have legal suffixes (LLC, Inc., Ltd.) stripped for matching purposes. Dates are converted to ISO 8601. State abbreviations are expanded to full names for consistency.
Step 3 — Run fuzzy matching
A multi-field fuzzy match job runs across first name, last name, email domain, company name, and phone number. Weighted scoring surfaces 47,000 probable duplicate pairs above the 85% confidence threshold. The top 10,000 pairs (confidence > 95%) are auto-merged using survivorship rules; the remaining 37,000 pairs are presented for human review via the Match Data Pro review queue.
Step 4 — Verify addresses via CASS
All 850,000 US address records are submitted to CASS verification. 9% fail — either non-deliverable or structurally invalid. These are flagged for outreach or suppression from direct mail lists.
Step 5 — Export the golden record set
The clean output: 791,000 deduplicated, standardised, address-verified records — ready for CRM reimport, marketing segmentation, or analytics ingestion. The full match-and-merge pipeline ran in under 40 minutes.
Common Data Cleansing Mistakes to Avoid
Even experienced data teams repeat the same cleansing mistakes. The most costly include:
- Cleansing without profiling first. Applying transformation rules blind leads to over-correction and data loss. Always profile before you touch a field.
- Using exact-match deduplication only. Exact matching misses the majority of real-world duplicates, which differ by a single character, abbreviation, or typo. Fuzzy matching is non-negotiable for CRM, contact, and entity data.
- Applying irreversible transforms without lineage. If you overwrite source data without preserving the original values, you cannot audit what changed or roll back an error. Always maintain a change log.
- Treating data cleansing as a one-time project. New data is ingested continuously. A cleansing pipeline that runs once produces a clean snapshot that degrades the moment new records arrive. Scheduled, automated cleansing jobs are the only sustainable model.
- Ignoring downstream consumers. A field transformation that makes data cleaner in isolation may break a downstream join, dashboard, or API contract. Cleansing changes must be socialised with pipeline owners.
For deeper coverage of best practice, see our guide: What Are the Best Practices for Data Cleansing in 2026?
Automating Data Cleansing with Match Data Pro
Manual and script-based cleansing pipelines have a ceiling. At the volumes data teams now routinely manage — tens of millions of records across CRM, ERP, data warehouse, and third-party feeds — automation is the only viable path. Match Data Pro is built for exactly this workload.
Key platform capabilities for data cleansing
- AI Data Profiling: Automated quality scoring, null analysis, format detection, and anomaly surfacing across any structured dataset on import.
- Configurable Fuzzy Matching: Choose from Levenshtein, Jaro-Winkler, Soundex, Metaphone, and custom phonetic algorithms. Weight fields independently. Set confidence thresholds per match rule.
- Deduplication at Scale: Blocking and indexing strategies allow fuzzy deduplication across millions of records without combinatorial explosion.
- Senzing Entity Resolution: Graph-based probabilistic resolution for cross-source, multi-entity identity matching where simple fuzzy logic is insufficient.
- CASS Address Verification: USPS-certified address parsing, correction, and ZIP+4 appending built directly into the cleansing workflow.
- Job Automation: Schedule recurring cleansing jobs via cron or event trigger. No manual re-runs required.
- Import/Export Connectors: Connect to Salesforce, HubSpot, SQL databases, flat files, and APIs. Clean data where it lives, then push results back.
Match Data Pro is available as a no-contract SaaS subscription or as an on-premise / private cloud deployment for organisations with data residency requirements. See our flexible pricing options or compare data cleansing tools for 2026.
Frequently Asked Questions: Data Cleansing
What is the difference between data cleansing and data transformation?
Data cleansing focuses on correcting quality defects within existing data — fixing errors, removing duplicates, standardising formats, and filling or flagging nulls. Data transformation is a broader term that includes reshaping data for a target schema (e.g., pivoting columns, aggregating rows, or converting data types for a warehouse load). Cleansing is often a prerequisite step within a broader ETL or ELT transformation pipeline.
How long does data cleansing take for a large dataset?
The duration depends on dataset size, defect complexity, and the tooling used. A manual approach for 100,000 records can take days or weeks. An AI-powered platform like Match Data Pro can profile, deduplicate, and standardise a dataset of 1–2 million records in under an hour, with automated job scheduling enabling continuous background cleansing as new data arrives.
Can data cleansing be fully automated?
Most of the cleansing pipeline — profiling, standardisation, format validation, high-confidence deduplication, and address verification — can and should be automated. The remaining fraction involves genuine ambiguity: near-duplicate pairs where additional context is needed. Best-practice platforms surface only these edge cases to human reviewers, keeping manual effort to under 5% of total records for well-defined use cases.
What is the difference between data cleansing and data quality management?
Data cleansing is a reactive, operational process: you detect and fix defects that already exist in a dataset. Data quality management (DQM) is a broader, proactive governance framework: it defines quality dimensions (accuracy, completeness, consistency, timeliness), sets measurable thresholds, assigns data stewardship accountability, and embeds quality checks at the point of data entry and ingestion — reducing the number of defects that accumulate in the first place. Cleansing is a component of DQM, not a substitute for it.
How do I choose a data cleansing threshold for fuzzy matching?
Threshold selection depends on the risk profile of false positives versus false negatives in your use case. For a marketing suppression list, a 75% similarity threshold may be acceptable — better to suppress a probable duplicate than send a conflicting message. For a financial ledger merge, a 95%+ threshold is more appropriate — the cost of incorrectly merging two distinct entities is higher. Start with profiling to understand your data’s natural similarity distribution, then calibrate thresholds using a labelled sample before running at scale.
Start Cleansing Your Data Today
Data cleansing is not optional — it is the foundation that every downstream analytics, AI, and operational workflow stands on. The question is not whether to invest in it, but how to do it efficiently and at scale.
Match Data Pro gives data engineers and RevOps teams a complete, AI-powered data cleansing platform: profiling, fuzzy matching, deduplication, entity resolution, CASS address verification, and job automation — in a single no-contract SaaS subscription or on-premise deployment.
Start your free trial — no contract, no commitment, results in minutes.
Or book a personalised demo with our team: sales@matchdatapro.com