
Data cleansing is the process of identifying and correcting — or removing — inaccurate, duplicate, incomplete, and inconsistent records from a dataset so that it is accurate, consistent, and ready for analysis or operational use. For data engineers managing enterprise pipelines and RevOps teams relying on CRM accuracy, data cleansing is not a one-time project — it is a continuous discipline that directly determines the quality of every downstream decision, report, and AI model your organization runs.

Why Data Cleansing Is a Business-Critical Priority in 2026
The financial stakes around data quality have never been higher. According to a 2025 IBM Institute for Business Value report, 43% of chief operations officers identify data quality issues as their most significant data priority — and over a quarter of organizations estimate they lose more than $5 million annually due to poor data quality. Gartner puts the average annual cost of poor data quality at $12.9 million per organisation.
The consequences compound in AI-driven environments. When poor quality data enters machine learning workflows, its inaccuracies, biases, and inconsistencies propagate across downstream systems — diminishing business value and operational efficiency at scale. With AI spending forecast to surpass $2 trillion in 2026, the margin for dirty data is effectively zero.
Beyond AI, the operational impact is equally severe. A Gartner report found that 50% of employees spend more than one hour per day correcting data mistakes or searching for accurate information — a direct drag on productivity that compounds across every team touching your data.
What Data Cleansing Actually Covers: 6 Core Operations
Data cleansing is not a single action. It is a structured pipeline of six interdependent operations, each targeting a specific class of data quality problem.
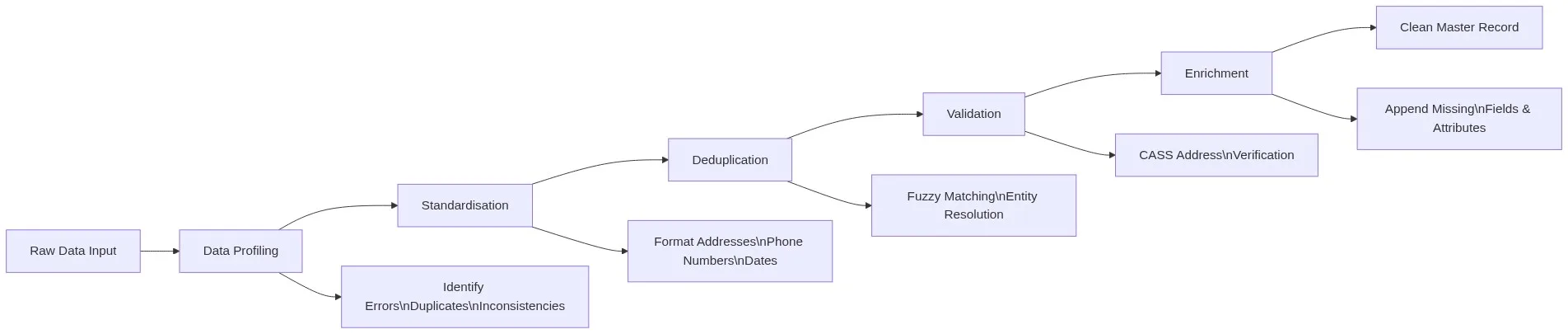
1. Data Profiling
Before touching a single record, you must understand what you are working with. Profiling gives you a high-level view of data quality issues — null rates, format inconsistencies, value distributions, and duplicate counts — and helps you prioritise what actually needs fixing. This initial audit often reveals systematic patterns, such as entire columns with gaps or categories that should be merged. Profiling first saves significant remediation time later.
Match Data Pro’s AI Data Profiling module automates this step, scanning millions of records and surfacing quality issues in minutes rather than days.
2. Standardisation
Raw data from multiple sources arrives in inconsistent formats. Phone numbers may be formatted as (555) 123-4567, 555-123-4567, or +15551234567. Addresses may abbreviate “Street” as “St”, “St.”, or “Street”. Standardisation normalises all values to a defined canonical format — a prerequisite for any accurate matching or deduplication to follow.
This includes standardising capitalisation, spelling, and abbreviations. In 2026, NLP techniques using semantic similarity can normalise entries that rule-based systems miss entirely — for example, “Intl” versus “International” versus “Int’l”.
3. Deduplication
Duplicate records are the single most common data quality problem in enterprise CRM, ERP, and marketing databases. A customer who has entered their name as “Robert Smith”, “Bob Smith”, and “R. Smith” across three touchpoints is three records in your system — but one person in reality. Standard exact-match deduplication catches only obvious duplicates. Fuzzy matching — using algorithms such as Jaro-Winkler, Levenshtein distance, and phonetic matching — identifies near-duplicate records that share the same underlying entity despite surface-level differences in spelling, formatting, or data entry errors.
Match Data Pro processes 2 million records in under 5 minutes using its AI-powered fuzzy matching engine — making large-scale enterprise deduplication operationally viable without batch overnight jobs.
4. Validation
Validation turns data quality from a manual, reactive task into a repeatable safeguard. Rule-based checks verify that data complies with explicit, predefined conditions derived from business logic: valid date ranges, correct email formats, postal codes that match cities, phone numbers with the right digit counts. Every dataset used for reporting, analysis, or modelling should pass a standard validation check before it is considered usable.
For US address data specifically, CASS (Coding Accuracy Support System) address verification — the USPS-certified standard — validates and corrects postal addresses to deliverability standards, catching address errors that generic validation rules miss.
5. Entity Resolution
Entity resolution goes beyond deduplication of individual fields. It answers the question: across all your data sources, which records refer to the same real-world entity — person, company, address, or product? This is particularly critical for organisations merging CRM systems, integrating acquired company data, or consolidating records across business units.
Match Data Pro integrates Senzing entity resolution — a probabilistic engine that resolves entities across billions of records with high precision, building a unified master record that survives future data ingestion without manual intervention.
6. Enrichment
Once records are clean and deduplicated, enrichment appends missing or outdated fields from authoritative third-party sources — company size, industry classification, verified email addresses, LinkedIn URLs, firmographic data. Enrichment turns a minimal contact record into a complete, actionable profile that your sales and marketing teams can act on immediately.
Data Cleansing vs. Data Transformation: Understanding the Difference
These two terms are often conflated but serve fundamentally different purposes in a data pipeline:
| Dimension | Limpieza de datos | Data Transformation |
|---|---|---|
| Purpose | Fix quality issues in existing data | Convert data from one structure or format to another |
| Examples | Remove duplicates, fix typos, validate addresses | Pivot tables, aggregate metrics, join datasets |
| When it runs | Before transformation and loading | After cleansing, as part of ETL/ELT |
| Output | Accurate, consistent source data | Structured data ready for analysis or reporting |
In practice, cleansing always precedes transformation. Transforming dirty data produces dirty insights — and no amount of downstream processing recovers data quality that was never established at the source.
Data Cleansing Best Practices for Enterprise Teams
The technical steps above are necessary but not sufficient. Sustainable data quality at enterprise scale requires organisational practices that make cleansing continuous rather than episodic.
Define Quality Standards Before You Cleanse
Data quality standards provide rules and guidelines for validating and formatting data and ensuring consistency during the cleansing process. Before touching a dataset, define what “good data” means for your specific use case — acceptable ranges, formats, completeness thresholds, and error tolerances. When standards are defined upfront, cleaning becomes a structured process rather than a series of subjective fixes.
Profile First, Then Plan
Data teams should begin with a comprehensive audit of their data so they can fully understand the scope of their cleansing efforts. This includes profiling the data to understand its structure, content, and relationships. Without this step, teams frequently fix symptoms while missing root causes — expending effort on surface corrections while systematic upstream issues continue generating new dirty records.
Automate and Shift Left
Manual cleanup does not scale. Implement automated data quality checks at the point of ingestion — the “Shift Left” principle — rather than waiting until errors have propagated through your systems. Automated data cleaning tools save significant time and resource, and a continuous approach to monitoring data quality catches issues before they reach dashboards and decision-makers.
Schedule Routine Cleansing Cadences
Depending on data volume and velocity, organisations should schedule routine data cleaning at least monthly, quarterly, or annually as a minimum. For CRM and marketing data specifically, contact data decays rapidly — studies suggest nearly three-quarters of contact records contain at least one change within 12 months. A reactive cleansing approach guarantees your database is perpetually stale.
Apply Fuzzy Matching for Deduplication — Not Just Exact Match
Data deduplication and fuzzy data matching are among the most effective ways to streamline operations at scale. Exact-match deduplication misses the majority of real-world duplicates because human data entry is inconsistent. A fuzzy matching engine that scores record similarity across multiple fields — name, address, phone, email — and surfaces probable matches for automated or manual review is the only approach that works at enterprise data volumes.
Data Cleansing for CRM and RevOps Teams
For Revenue Operations teams, data cleansing is not an abstract engineering problem — it directly determines pipeline accuracy, sales rep productivity, and marketing campaign ROI.
Common CRM data quality issues that fuzzy matching and cleansing tools address include:
- Duplicate contacts and accounts — same person entered multiple times across campaigns, imports, and manual entry
- Inconsistent company names — “IBM”, “I.B.M.”, “International Business Machines” as separate accounts
- Invalid email addresses — formatting errors, domain typos, role addresses that bounce
- Incomplete records — missing phone, title, or industry fields that prevent effective segmentation
- Stale data — contacts who have changed jobs, companies that have rebranded or been acquired
Match Data Pro’s deduplication engine integrates directly with CRM exports, running fuzzy match scoring across name, email, phone, and address fields simultaneously — producing a ranked list of probable duplicates with configurable merge rules that your RevOps team controls.
Choosing a Data Cleansing Tool: What to Evaluate
For large-scale enterprises processing real-time data, a purpose-built data quality platform is significantly more effective than open-source tools or manual processes. When evaluating platforms, prioritise:
- Scalability — can it process your current and projected data volumes without latency? Match Data Pro handles 2 million records in under 5 minutes.
- Fuzzy matching quality — does it go beyond exact match? What algorithms does it support? Are match thresholds configurable?
- Address verification — is CASS certification included for US address validation?
- Entity resolution — can it resolve entities across multiple source systems, not just within a single dataset?
- Deployment flexibility — SaaS for fast deployment, on-premise or private cloud for sensitive data environments
- Automation — can cleansing jobs be scheduled, triggered by API, or run as part of a broader data pipeline?
- No-contract terms — enterprise data projects change; avoid platforms that lock you into multi-year commitments before you have validated the fit
Frequently Asked Questions: Data Cleansing
What is the difference between data cleansing and data cleaning?
There is no technical difference — data cleansing and data cleaning are interchangeable terms for the same process: identifying and correcting errors, duplicates, and inconsistencies in a dataset. “Data cleansing” is more commonly used in enterprise and B2B contexts; “data cleaning” appears more frequently in data science and academic contexts. Both refer to the same operational discipline.
How long does data cleansing take for a large enterprise dataset?
With manual processes, cleansing a dataset of one million records can take weeks. With an AI-powered automated platform like Match Data Pro, the same dataset can be profiled, deduplicated, standardised, and validated in minutes. Match Data Pro processes 2 million records in under 5 minutes — making enterprise-scale cleansing operationally viable as a routine, scheduled process rather than a major project.
How often should data cleansing be performed?
Best practice is to build cleansing into your ongoing data pipeline rather than treating it as a periodic project. At a minimum, organisations should cleanse data monthly. High-velocity data environments — active CRM databases, e-commerce customer records, marketing contact lists — benefit from continuous automated cleansing at the point of ingestion. Contact data in particular decays quickly; nearly three-quarters of contact records contain at least one change within 12 months.
What is fuzzy matching and why is it needed for data cleansing?
Fuzzy matching is a technique that identifies records which are likely to refer to the same real-world entity despite differences in spelling, formatting, or data entry — for example, “Robert Smith” and “Bob Smith” at the same address. Standard exact-match deduplication misses these near-duplicate records entirely. Fuzzy matching algorithms — including Jaro-Winkler, Levenshtein distance, and phonetic matching — score the similarity between record pairs and surface probable matches above a configurable threshold, enabling far more comprehensive deduplication than exact matching alone.
What is the difference between data cleansing and data governance?
Data cleansing is the operational process of finding and fixing quality issues in specific datasets. Data governance is the organisational framework — policies, roles, standards, and accountability structures — that defines how data should be collected, stored, and managed across the enterprise. Governance without cleansing produces well-documented bad data. Cleansing without governance produces clean data that becomes dirty again immediately. Sustainable data quality requires both: governance sets the standards, and cleansing enforces them continuously.
Start Cleansing Your Data Today
Match Data Pro combines AI-powered fuzzy matching, automated deduplication, CASS address verification, Senzing entity resolution, and AI data profiling in a single platform — available as SaaS or on-premise deployment, with no long-term contract required.
Start your free trial and run your first data cleansing job in minutes — or book a demo with our team to walk through your specific data environment.