

¿Qué es el emparejamiento difuso?
Fuzzy matching is a technique that finds records, strings, or data values that are similar but not identical. Instead of requiring an exact character-for-character match, fuzzy matching calculates a similarity score between two values and returns matches above a configurable threshold. It is also known academically as approximate string matching.
In plain terms: fuzzy matching is what lets a system recognise that “Robert Smith”, “Rob Smith”, and “R. Smyth” are probably the same person — even though none of those strings match exactly.
It is a foundational technique in data quality, record linkage, entity resolution, and deduplication — anywhere real-world data is messy, inconsistently entered, or drawn from multiple sources that were never designed to talk to each other.
Fuzzy Matching vs Exact Matching
The difference is straightforward but the implications are significant.
| Exact Matching | Coincidencia difusa |
|---|---|
| Returns a match only if values are identical | Returns matches above a similarity threshold |
| “Smith” ≠ “Smyth” → no match | “Smith” vs “Smyth” → 0.91 score → match |
| Fast, deterministic | Slower, probabilistic |
| Fails on typos, abbreviations, formatting differences | Handles typos, abbreviations, transpositions |
| Best for structured IDs, codes, barcodes | Best for names, addresses, company names, free text |
Exact matching is the right tool when your data is clean and structured — matching SKUs, transaction IDs, or country codes. Fuzzy matching is the right tool when your data was entered by humans, imported from multiple systems, or collected over time without consistent formatting standards.
Fuzzy Matching Examples
Here are real-world fuzzy matching examples across common data types:
Name Matching
- “William Johnson” vs “Bill Johnson” — nickname variation
- “Jennifer O’Brien” vs “Jennifer Obrien” — punctuation dropped
- “Dr. Sarah Chen” vs “Sarah Chen” — title prefix
- “Mohammed Al-Rashid” vs “Mohammad Alrashid” — transliteration difference
Company Name Matching
- “Acme Corporation Ltd” vs “ACME Corp” — abbreviation + case
- “Google LLC” vs “Google, Inc.” — legal suffix variation
- “3M Company” vs “3M Co.” — shortened form
Address Matching
- “123 Main Street” vs “123 Main St.” — abbreviated suffix
- “Apt 4B, 500 Oak Ave” vs “500 Oak Avenue #4B” — reordered components
Product / Record Matching
- “iPhone 14 Pro 256GB Space Black” vs “Apple iPhone14 Pro 256 GB Blk” — spacing and abbreviation
In every case, exact matching returns zero results. Fuzzy matching returns the correct link.
How Fuzzy Matching Works: The Algorithms
Fuzzy matching works by applying a similarity algorithm to two strings, producing a score between 0.0 (completely different) and 1.0 (identical). The score is then compared against a threshold — typically 0.80 to 0.95 depending on the use case — to decide whether the two values represent a match.
Different algorithms are suited to different data types and error patterns. Here are the four main families:
1. Levenshtein Distance (Edit Distance)
Levenshtein distance — the most widely taught fuzzy matching algorithm — counts the minimum number of single-character edits required to transform one string into another. Those edits are: insertions, deletions, and substitutions.
- Example: “kitten” → “sitting” requires 3 edits → Levenshtein distance = 3
- Example: “Smith” → “Smyth” requires 1 substitution → distance = 1, similarity ≈ 0.80
- Best for: Short strings with character-level typos
- Watch-out: Treats all edits as equal cost; does not reward matching prefixes or adjacent transpositions well
Levenshtein distance forms the basis of edit distance as a family of algorithms. Variants include Damerau-Levenshtein (which also handles transpositions — “teh” vs “the”) and the Longest Common Subsequence.
2. Jaro-Winkler Similarity
Jaro-Winkler was specifically designed for short strings and proper names — which is why it is the algorithm of choice in most people-matching and customer data contexts.
- It rewards strings that share common characters within a proximity window
- The Winkler extension adds a prefix bonus — strings that share the same starting characters score higher
- Example: “MARTHA” vs “MARHTA” → Jaro-Winkler ≈ 0.96 (transposition handled well)
- Example: “Johnathan” vs “Jonathan” → Jaro-Winkler ≈ 0.97
- Best for: Personal names, given names, short identifiers
- Watch-out: Less effective on long strings or compound values
Match Data Pro uses Jaro-Winkler as one of its core configurable algorithms for name and entity matching — precisely because of its strength on personal name data.
3. Token-Based Matching
Token-based methods split strings into individual words (tokens) before comparing. This handles cases where the same information appears in different orders.
- Token Sort: Sorts tokens alphabetically before comparing — “Smith, John” and “John Smith” become the same string
- Token Set Ratio: Compares the intersection and remainder of token sets — handles partial matches and extra words
- Example: “New York City Police Department” vs “NYPD New York” — token overlap identifies a likely match even with abbreviation
- Best for: Long strings, company names, addresses, product descriptions
4. Phonetic Matching
Phonetic matching converts strings to a phonetic code before comparing — so names that sound the same match even if spelled differently.
- Soundex: The original phonetic algorithm (1918), encodes names to a letter + 3 digits. “Smith” and “Smyth” both encode to S530.
- Metaphone / Double Metaphone: More accurate modern alternative, handles more pronunciation rules and non-English names
- Example: “Catherine” and “Kathryn” and “Katherine” all produce the same Metaphone code
- Best for: Names entered phonetically, multilingual data, spoken-word transcription
- Watch-out: Phonetic matching alone produces high false-positive rates — best used in combination with other algorithms
How the Algorithms Compare
| Algorithm | Lo mejor para | Handles Transpositions | Handles Word Order | Handles Sound-Alikes |
|---|---|---|---|---|
| Levenshtein | Short strings, typos | Partial | ❌ | ❌ |
| Jaro-Winkler | Names, short identifiers | ✅ | ❌ | ❌ |
| Token-Based | Long strings, addresses | ✅ | ✅ | ❌ |
| Phonetic | Sound-alike names | ✅ | ❌ | ✅ |
In practice, production-grade fuzzy matching systems — including Match Data Pro — combine multiple algorithms and weight the results, rather than relying on any single method.
How Fuzzy Matching Works: Step by Step
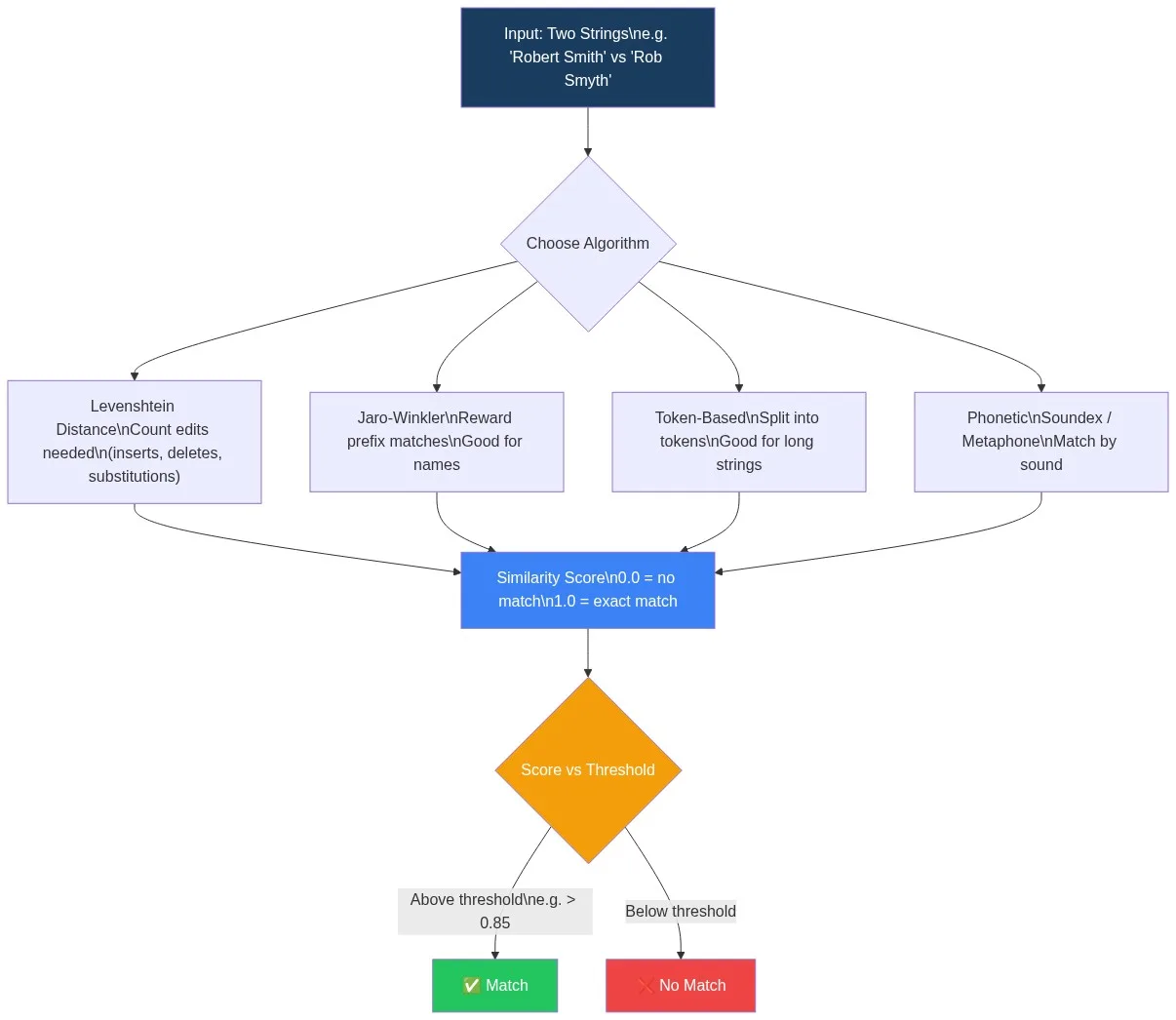
- Input: Two strings (or two datasets of strings) are passed to the matching engine.
- Pre-processing: Strings are normalised — lowercased, punctuation stripped, common abbreviations expanded (e.g. “St.” → “Street”).
- Algorithm selection: One or more similarity algorithms are applied — Levenshtein, Jaro-Winkler, token-based, phonetic, or a combination.
- Scoring: Each algorithm returns a similarity score between 0.0 and 1.0.
- Threshold comparison: The score is compared against a configurable threshold (e.g. 85%). Pairs above the threshold are flagged as matches; pairs below are not.
- Review or automation: High-confidence matches can be auto-merged. Borderline matches can be routed to a human review queue. Low-confidence pairs are discarded.
Fuzzy Matching in Data — Real-World Applications
Fuzzy matching in data pipelines is one of the most common — and most underestimated — data quality challenges. Here is where it appears most often:
- CRM deduplication: Identifying duplicate customer records created through different channels (web form, phone, import)
- MDM / entity resolution: Resolving the same customer, supplier, or product across ERP, CRM, and marketing platforms
- KYC and compliance: Matching customer names against sanctions lists, PEP databases, and watchlists — where name transliteration differences are common
- E-commerce product matching: Identifying the same product listed by multiple suppliers under slightly different names
- Inventory matching: Reconciling the same item across supplier feeds, warehouse systems, and your own catalogue — where the same product appears under inconsistent names, SKUs, and abbreviations (e.g. “HP LaserJet Pro M404dn” vs “HP LaserJet-Pro M404 dn”). An 85% threshold typically catches these variants without merging genuinely different items.
- Healthcare record linkage: Connecting patient records across hospitals and systems where name spelling, DOB entry, and address format varies
- Address standardisation: Matching submitted addresses against a reference database to verify and clean them
- Fraud detection: Identifying applications from the same individual using slightly varied identity details
Fuzzy Matching in Excel
Excel does not have a native fuzzy match function, but there are three practical approaches:
Option 1 — Power Query Fuzzy Merge (Built-In)
Excel’s Power Query includes a “Fuzzy Matching” option in the Merge Queries dialog (available in Excel 365 and Excel 2019+). It uses a token-based similarity algorithm and lets you set a similarity threshold. It works well for small to medium datasets but has no visibility into the underlying scores.
Steps: Data → Get & Transform → Merge Queries → tick “Use fuzzy matching to perform the merge”
Option 2 — VLOOKUP + Manual Levenshtein Formula
You can implement a basic edit distance calculation in Excel using a recursive VBA function or array formula. This works but is slow beyond a few thousand rows and requires VBA knowledge.
Option 3 — Dedicated Tool with Excel Import/Export
For anything beyond a simple one-off lookup, a dedicated fuzzy matching platform like Match Data Pro is faster and more reliable. Upload your Excel file, configure matching rules, download results. No formulas, no VBA, no row limits.
Try Match Data Pro free with your own Excel data →
Fuzzy Matching with AI and ChatGPT
AI — including large language models like ChatGPT — can perform fuzzy matching, but with important limitations compared to dedicated algorithms.
What AI Does Well
- Contextual understanding — recognising that “IBM” and “International Business Machines” are the same entity using world knowledge, not string similarity
- Handling highly ambiguous or multilingual name variations
- Explaining why two records are or are not a match in natural language
Where AI Falls Short for Production Matching
- Scale: LLM API calls cost significantly more per comparison than algorithmic matching — impractical for millions of record pairs
- Consistency: LLMs are non-deterministic — the same input can produce different outputs on different runs
- Auditability: You cannot easily inspect or justify an LLM match decision for compliance or data governance purposes
- Latency: API round-trips add seconds per comparison; algorithmic matching runs thousands of comparisons per second
Is Fuzzy Matching AI?
Traditional fuzzy matching algorithms (Levenshtein, Jaro-Winkler, Soundex) are not AI — they are deterministic mathematical functions. However, modern matching platforms increasingly layer AI on top: using machine learning to suggest match thresholds, identify which fields matter most, and learn from human corrections over time. Match Data Pro uses AI-powered match suggestions alongside its configurable algorithmic core — combining the consistency and speed of algorithms with the contextual intelligence of AI.
Fuzzy Matching vs Entity Resolution — What’s the Difference?
These terms are related but not the same:
- Fuzzy matching — a technique for scoring similarity between two strings. It answers: how similar are these two values?
- Record linkage — using fuzzy matching and other signals to decide whether two records from different datasets refer to the same real-world entity
- Entity resolution — the full process of identifying, linking, and consolidating all records that refer to the same entity across an entire dataset or multiple systems, producing a canonical “golden record”
Fuzzy matching is an input to record linkage. Record linkage is a component of entity resolution. Entity resolution is the end goal in most MDM and data quality programs.
Choosing the Right Fuzzy Matching Threshold
The threshold — the minimum similarity score required to flag a match — is the most consequential configuration decision in any fuzzy matching project.
| Threshold | Effect | Risk | Lo mejor para |
|---|---|---|---|
| 95%-100% | Only near-perfect matches | High false negatives (misses real duplicates) | Low-risk automated merging |
| 85%-94% | Strong matches, handles common typos | Balanced | Most CRM / MDM deduplication |
| 70%-84% | Catches more variations — nicknames, abbreviations | Higher false positives (wrong matches) | Human review queue, KYC screening |
| Below 70% | Very broad — many candidate pairs returned | High false positive rate | Exploratory analysis only |
Is 85% a common threshold? Yes — an 85% similarity threshold (0.85) is the most widely used default in CRM and MDM deduplication, and it’s a sensible starting point for most name and company-matching projects. It’s popular because it sits in the sweet spot: high enough to reject most coincidental matches, but low enough to still catch the everyday variations — typos, dropped punctuation, abbreviations — that exact matching misses. An 85% threshold means two values must score at least 0.85 out of 1.0 to be flagged as a match. In practice, “Smith” vs “Smyth” scores around 0.80 (just under, so not matched at 85%), while “Robert Smith” vs “Robert Smyth” scores well above 0.85 and is matched. Most teams start at 85%, review the borderline results, then tune up or down from there.
The right threshold depends on your data, your domain, and the cost of a false positive vs a false negative in your context. Match Data Pro lets you configure thresholds per field and preview match results before committing — so you can tune before you run.
Try Fuzzy Matching on Your Own Data
Match Data Pro is a cloud SaaS platform that combines configurable fuzzy matching (Jaro-Winkler and Levenshtein), AI-powered match suggestions, entity resolution, address verification, and data cleansing — all in a self-serve interface with transparent pricing and no long-term contract.
Start Your Free Trial — No Contract Required →
Frequently Asked Questions About Fuzzy Matching
What is fuzzy matching in simple terms?
Fuzzy matching finds records or values that are similar but not exactly identical. It handles typos, name variations, abbreviations, and formatting differences that would cause exact matching to fail. Instead of yes/no, it returns a similarity score — and you decide what score counts as a match.
What is a fuzzy matching algorithm?
A fuzzy matching algorithm is a mathematical method for calculating how similar two strings are. The most common are Levenshtein distance (counts character edits), Jaro-Winkler (rewards shared prefixes, designed for names), token-based methods (handles word-order differences), and phonetic algorithms like Soundex and Metaphone (matches by how words sound). Most production systems combine several algorithms.
What is the difference between fuzzy matching and exact matching?
Exact matching only returns a result when two values are character-for-character identical. Fuzzy matching returns results when values are similar enough — above a configurable similarity threshold. Exact matching is appropriate for structured identifiers (IDs, codes). Fuzzy matching is necessary for human-entered data: names, addresses, company names, and free text.
What is Levenshtein distance?
Levenshtein distance is the minimum number of single-character edits — insertions, deletions, or substitutions — needed to transform one string into another. A distance of 0 means the strings are identical. A distance of 1 means one character change separates them. It is the most widely used edit distance metric in fuzzy string matching and approximate string matching.
What is Jaro-Winkler similarity?
Jaro-Winkler is a string similarity algorithm designed specifically for short strings and proper names. It scores strings based on common characters within a proximity window, then adds a bonus for shared starting characters (the “Winkler” prefix bonus). It consistently outperforms Levenshtein on personal name matching tasks and is used in census record linkage, KYC, and CRM deduplication.
How do I do fuzzy matching in Excel?
Excel 365 and Excel 2019+ include a built-in Fuzzy Merge option in Power Query (Data → Get & Transform → Merge Queries → tick “Use fuzzy matching”). For larger datasets or more control over matching rules and similarity scores, a dedicated tool like Match Data Pro is faster and more flexible — upload your Excel file, configure rules, download results.
Is fuzzy matching the same as AI?
Traditional fuzzy matching algorithms are not AI — they are deterministic mathematical functions. However, modern platforms layer AI on top: using machine learning to suggest thresholds, identify the most discriminating fields, and learn from human match decisions. Match Data Pro combines algorithmic fuzzy matching with AI-powered match suggestions — you get the speed and consistency of algorithms with the contextual intelligence of AI.
Can ChatGPT do fuzzy matching?
ChatGPT and other large language models can identify similar strings and make match judgements using contextual knowledge — for example, knowing that “IBM” and “International Business Machines” are the same entity. However, they are not practical for production-scale fuzzy matching due to cost per comparison, non-determinism, latency, and lack of auditability. For matching millions of records, use a dedicated algorithmic platform.
What is approximate string matching?
Approximate string matching is the academic and computer-science term for what practitioners call fuzzy matching or fuzzy string matching. It refers to the problem of finding strings that approximately match a pattern, allowing for a defined number or type of differences. The two terms are interchangeable in data quality contexts.
What is fuzzy matching used for in data?
In data contexts, fuzzy matching is used for: deduplication (finding duplicate records in a single dataset), record linkage (connecting records across two or more datasets), entity resolution (building a single master view of a customer, supplier, or product from multiple sources), address standardisation, KYC and sanctions screening, product catalogue matching, and fraud detection. Anywhere human-entered or multi-source data needs to be connected, fuzzy matching is part of the solution.
Is 85% a good similarity threshold for fuzzy matching?
An 85% similarity threshold is the most common default and a reliable starting point for most fuzzy matching projects, especially CRM and MDM deduplication. It catches typos, abbreviations, and minor formatting differences while rejecting most false matches. Use a higher threshold (90–95%) when you’re auto-merging records and a wrong match is costly; use a lower one (70–84%) when a human reviews matches and you’d rather catch more candidates. The right number always depends on your data and the cost of a false match versus a missed one.
What does an 85% similarity threshold mean?
An 85% threshold means two values must score at least 0.85 on a scale from 0.0 (completely different) to 1.0 (identical) to be counted as a match. For example, “Jon Smith” vs “John Smith” scores above 0.85 and is matched, while “Jon Smith” vs “Jane Smith” falls below 0.85 and is not. Anything scoring 0.85 or higher clears the threshold; anything below is rejected or sent to review.
What threshold should I use for inventory matching?
For inventory and product matching, an 85% similarity threshold is a strong default — it links the same item listed under slightly different names, spacing, or SKUs across supplier and warehouse systems, while keeping distinct products apart. If your product names are long or contain shared boilerplate (brand, category, specs), pair the 85% threshold with token-based matching so word-order and extra terms don’t drag the score down.
Methodology & Disclosure
This guide is published by Match Data Pro, a data quality platform that includes fuzzy matching as a core capability. Algorithm descriptions and examples reflect established computer science literature on string similarity and approximate string matching, as of May 2026.